
1.4: Representing structures
- Page ID
- 225763
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Representing a chemical structure
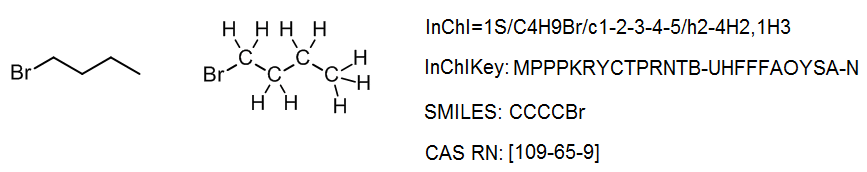
Introduction to structure drawing
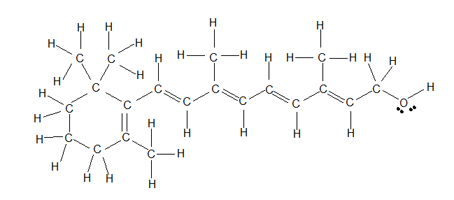
Observe the following drawings of the structure of retinol, the most common form of vitamin A. The first drawing follows a Lewis-based structure which is helpful when you want to look at every single atom; however, showing all of the hydrogen atoms makes it difficult to compare the overall structure with other similar molecules and makes it difficult to focus in on the double bonds and OH group.
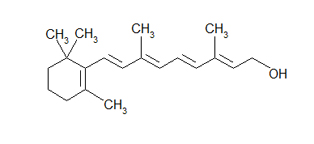
The following is a skeletal (a.k.a. line-angle) formula for retinol. With this simplified representation, one can easily see the carbon-carbon bonds, double bonds, OH group, and CH3 groups sticking off of the the main ring and chain. Also, it is much quicker to draw this than the one above.
Importance of structure
Learning and practicing the basics of organic chemistry will help you immensely in the long run as you learn new concepts and reactions. Some people say that organic chemistry is like another language, and in some aspects, it is. At first it may seem difficult or overwhelming, but the more you practice looking at and drawing organic molecules, the more familiar you will become with the structures and formulae. Another good idea is to get a model kit and physically make the molecules that you have trouble picturing in your head.
Through general chemistry, you may have already experienced looking at molecular structure. The different ways to draw organic molecules include Lewis-type, condensed formulae, and skeletal formulae. It will be more helpful if you become comfortable going from one style of drawing to another, and look at drawings and understanding what they mean, than knowing which kind of drawing is named what.
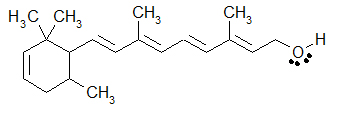
An example of a drawing that incorporates all three ways to draw organic molecules would be the following additional drawing of retinol. The majority of the drawing uses the skeletal formula, but the -CH3 are written as condensed formulae, and the -OH group is written in Lewis-type form.
Drawing the structure of organic molecules
Although larger molecules may look complicated, they can be easily understood by breaking them down and looking at their smaller components.
All atoms want to have their valence shell full, a “closed shell.” Hydrogen has a full shell with only 2 e– whereas carbon, oxygen, and nitrogen want to have 8 e–(an “octet”). When looking at the different representations of molecules, keep in mind the Octet Rule. Also remember that hydrogen can bond one time, oxygen can bond up to two times, nitrogen can bond up to three times, and carbon can bond up to four times.
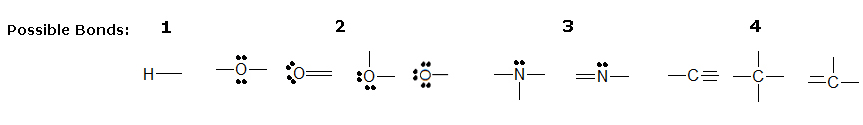 Lewis-type
Lewis-type
.jpg?revision=1)
Lewis-type structures are similar to traditional Lewis structures, but instead of covalent bonds being represented by electron dots, the two shared electrons are shown by a line.
(A) 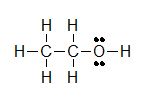
(B)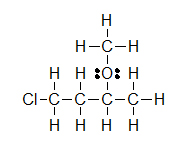
(C)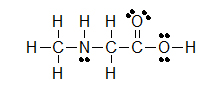
Lone pairs remain as two electron dots, but they are usually left out even though they are still there. Notice how the three lone pairs of electrons were not draw in around chlorine in example B.
Condensed formulae
A condensed formula is made up of the elemental symbols. The order of the atoms suggests the connectivity. Condensed formulas can be read from either direction and H3C is the same as CH3, although the latter is more common because Look at the examples below and match them with their identical molecule under Kekulé structures and bond-line formulas.
(A) CH3CH2OH (B) ClCH2CH2CH(OCH3)CH3 (C) H3CNHCH2COOH
Let’s look closely at example B. As you go through a condensed formula, you want to focus on the carbons and other elements that aren’t hydrogen. The hydrogens are important, but are usually there to complete octets. Also, notice the -OCH3 is in written in parentheses which tell you that it not part of the main chain of carbons. As you read through a a condensed formula, if you reach an atom that doesn’t have a complete octet by the time you reach the next hydrogen, then it’s possible that there are double or triple bonds. In example C, the carbon is double bonded to oxygen and single bonded to another oxygen. Notice how COOH means C(=O)-O-H instead of CH3-C-O-O-H because in the latter structure carbon does not have a complete octet and oxygens.
Skeletal formulae
Because of the typical (more stable) bonds that atoms tend to make in molecules, skeletal chains often end up looking like zig-zag lines. If you work with a molecular model kit you will find it difficult to make stick straight molecules (unless they contain sp triple bonds), whereas zig-zag molecules and bonds are much more feasible.
(A) 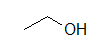
(B)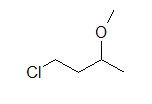
(C)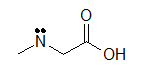
These molecules correspond to the exact same molecules depicted for Lewis-type structures and condensed formulae. Notice how the carbons are no longer drawn in and are replaced by the ends and bends of a lines. In addition, the hydrogens have been omitted, but could be easily drawn in (see practice problems). Although we do not usually draw in the H’s that are bonded to carbon, we do draw them in if they are connected to other atoms besides carbon (example is the OH group above in example A) . This is done because it is not always clear if the non-carbon atom is surrounded by lone pairs or hydrogens. Also in example A, notice how the OH is drawn with a bond to the second carbon, but it does not mean that there is a third carbon at the end of that bond/ line.
Problems
- How many carbons are in the following drawing? How many hydrogens?
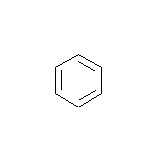
- How many carbons are in the following drawing? How many hydrogens?
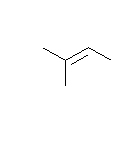
- How many carbons are in the following drawing? How many hydrogens?
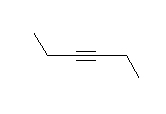
- Look at the following molecule of vitamin A and draw in the hidden hydrogens and electron pairs.
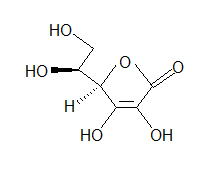 (Hint: Do all of the carbons have 4 bonds? Do all the oxygens have a full octet?)
(Hint: Do all of the carbons have 4 bonds? Do all the oxygens have a full octet?) - How many bonds can hydrogen make?
- How many bonds can chlorine make?
- Dashed lines means the atomic bond goes ___________(away/toward) you.
- Draw ClCH2CH2CH(OCH3)CH3 in Lewis and skeletal form.
[reveal-answer q=”797621″]Show Answer[/reveal-answer]
[hidden-answer a=”797621″]
- Remember the octet rule and how many times carbons and hydrogens are able to bond to other atoms.
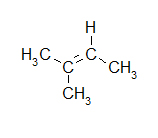
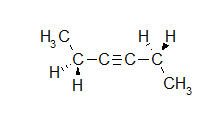
- Electron pairs drawn in blue and hydrogens drawn in red.
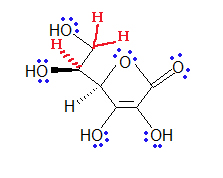
- Hygrogen can make one bond.
- Chlorine can make one bond.
- Away
- See (B) under Kekulé and Bond-line (zig-zag) formulas.
[/hidden-answer]
Further Reading
References
3. Vollhardt, K. Peter C., and Neil E. Schore. Organic Chemistry: Structure and Function. 5th ed. New York: W. H. Freeman Company, 2007. 38-40.
4. Klein, David R. Organic Chemistry I As a Second Language. 2nd ed. Hoboken, NJ: John Wiley & Sons, Inc, 2007. 1-14.
Outside Links
- Stereochemistry: http://en.wikipedia.org/wiki/Stereochemistry
- Retinol: http://en.wikipedia.org/wiki/Retinol
- Octet Rule: http://en.wikipedia.org/wiki/Octet_rule
- Lewis Structures: http://chemwiki.ucdavis.edu/index.php?title=Wikitexts/UCD_Chem_118A/ChemWiki_Module_Topics_for_Chem_118B/Lewis_Structures&highlight=lewis+structures
- sp hybrid orbitals: http://chemwiki.ucdavis.edu/index.php?title=Wikitexts/UCD_Chem_118A/ChemWiki_Module_Topics_for_Chem_118B/Hybrid_Orbitals&highlight=sp
- For drawing organic molecules on the computer: https://www.chemdoodle.com/
IUPAC Name
Traditionally, a chemical name was essential when a non–graphical representation was needed, for example in a chemical catalogue or handbook. In law, a chemical is often still represented by a name rather than a structure.[1] As a result, a set of rules has been developed to provide any structure with a systematic name. These rules have been approved by chemistry’s governing body, the International Union of Pure and Applied Chemistry (IUPAC), and are now well–established in chemistry publications. This ensures that when chemists communicate information through text, they can be certain they are referring to the same chemical structure. The main nomenclature rules can be found online in the IUPAC Blue Book,[2] and in any modern textbook on organic chemistry.
Computer–based identifiers
Once computers began to be used to store chemical information, it became necessary to design identifiers for chemical substances. Although structures can be drawn on computer, most structures being published in 2019 are simply image files, in which the chemical information cannot easily be read by computer. Most structure drawing software allows the user to save the structure as a Molfile, which contains the structure in a computer-readable table format suitable for chemical databases, etc. Nevertheless, many saw a need for a more concise way to represent chemical structures for computers in a single string (line of characters). These can be divided into “registry lookup” identifiers, which are in effect the listing number in a database (with no intrinsic chemical information), and “linear notations” which encapsulate the structural information in a single string.
Since 1965, Chemical Abstracts Service (CAS) has allocated “registry lookup” identifiers, called CAS Registry Numbers, for every substance in its database.[3] Each number is unique for a given substance. The number is assigned by CAS and does not contain structural information in the number; as such, it represents an actual substance (usually one that has been reported in the literature) rather than a structure (which may be only theoretical). CAS Registry Numbers are now used widely outside CAS as substance identifiers, for example in the US government list of “Chemicals of Interest” for Homeland Security.[4]
Other identifiers were then developed based on line notations that encoded structural information in the identifier.[5] One important such identifier is SMILES, developed in the 1980s as a machine-readable format that is “human-friendly”; simple structures can easily be read from a SMILES string either by a a computer or a trained chemist.[6]
International Chemical Identifier (InChI)
The most important of structural representation for computers is the InChI, which is also considered by IUPAC to be the “official” machine representation. Although it was only published first in 2005, it quickly became established as a valuable way to communicate structural information via the internet.7 Unlike many identifiers, the InChI algorithm is available for use under an open copyright, so that it can be freely generated and used without risk of copyright violation.
It is not important for a scientist to know how to read or write an InChI from scratch; any chemical drawing program can perform this task with ease. However, it is instructive to understand how the InChI is constructed, and how to use it. Consider a simple structure such as 2-bromobutane, which has the structure and InChI shown below:

The InChI is a string of characters that uses a series of “layers” to indicate various levels of structural detail. In this way, chemists can communicate information at the appropriate level of detail. Every InChI starts with “InChI=” followed by the version number, which in this case is version 1. The “S” indicates that the InChI is “standard” and does not include any optional information. The rest of the InChI is organized in layers, where each layer starts with a forward slash “/”. These sub-layers show: chemical formula, atom connections (beginning with /c), and hydrogen atoms (beginning with /h). For example, for 2-bromobutane, we have:
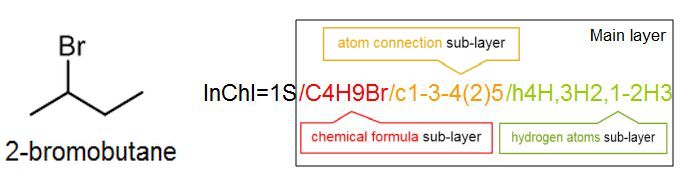
In some cases we may want to indicate a higher level of detail, for example the 3D–orientation of the atoms or stereochemistry. For this we use an additional layer at the end, in this case the stereochemistry layer (beginning with /t, /m and /s), to give an InChI which is unique for that specific stereoisomer:

One useful aspect of this layered structure is that similar structures have similar InChIs. For example, all isomers with the formula C4H9Br will begin with C4H9Br in the chemical formula sub-layer; in a database, these isomers can be easily identified. Likewise, two stereoisomers will have the same main layer, and only differ in the stereochemical layer. Many simple organic compounds will have just the main layer in their InChI.
An InChI of this sort can be found in Wikipedia and most online chemical databases such as PubChem and ChemSpider, where it is considered to be one of the main types of chemical identifier.[7] An InChI can be generated from a chemical structure in most modern structure drawing programs, such as BioviaDraw, ChemDraw, ChemSketch or ChemDoodle. These programs also allow the reverse – to input an InChI and use it to generate a chemical structure.
InChIKey
For larger molecules, the InChIKey can become large and unwieldy, making it difficult to use for certain applications, notably Web searches. Many search engines truncate long search strings, so later characters are lost from the search. For this reason the InChIKey was created, where the InChI (or structure) is converted to a 27 character string (including two dashes) based on a sequence of only upper case letters. The InChIKey is most used for Web searches. For example, the full InChI for morphine is InChI=1S/C17H19NO3/c1-18-7-6-17-10-3-5-13(20)16(17)21-15-12(19)4-2-9(14(15)17)8-11(10)18/h2-5,10-11,13,16,19-20H,6-8H2,1H3/t10-,11+,13-,16-,17-/m0/s1, whereas the InChIKey is simply BQJCRHHNABKAKU-KBQPJGBKSA-N .
This conversion to the InChIKey uses a “hash” function, which scrambles the InChI coding in order to generate an InChIKey that is as close to unique as possible. One unfortunate side effect of this is that once scrambled as the InChIKey, a structure cannot be converted back to an InChI or structure. This in turn means that the structure encoded in an InChIKey can only be found by comparing it against a list of known InChIKeys, known as a “lookup table”. If the InChIKey is for a new or unknown substance, the InChIKey cannot allow the user to identify what the molecule is.
As with the InChI itself, InChIKeys can be generated at will using any standard structure drawing program. Copying the InChIKey into a search engine allows the user to quickly find documents on the Web that relate to that specific structure.
Summary
Chemical structures may be represented in many ways, such as IUPAC names or computer-friendly line notations such as InChI. The InChI embeds the structural information in a series of “layers”, and it can be converted back to the original structure. It is useful for storing chemical structure information in databases. Meanwhile the InChIKey is a hashed version of the InChI which is mainly used to search chemical structures on the Web.
[5] Heller, Stephen R.; McNaught, Alan; Pletnev. Igor; Stein, Stephen; Tchekhovskoi, Dmitrii. “InChI, the IUPAC International Chemical Identifier.” Journal of Cheminformatics, 2015, 7:23.
[7] Warr, W.A. “Many InChIs and quite some feat” J. Comput. Aided Mol. Des., 2015, 29: 681. https://doi.org/10.1007/s10822-015-9854-3
- Structure of Organic Molecules. Authored by: Choo, Ezen (2009, UCD '11). Located at: https://chem.libretexts.org/Core/Organic_Chemistry/Fundamentals/Structure_of_Organic_Molecules. Project: Chemistry LibreTexts. License: CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- InChI Student Worksheet. Authored by: Steven Wathen. Provided by: InChI Trust. Located at: https://www.inchi-trust.org/inchi-post/inchi-student-worksheet/. License: CC BY-SA: Attribution-ShareAlike