
3.5: Statistical Analysis of Data
- Page ID
- 219791

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)A confidence interval is a useful way to report the result of an analysis because it sets limits on the expected result. In the absence of determinate error, a confidence interval based on a sample’s mean indicates the range of values in which we expect to find the population’s mean. When we report a 95% confidence interval for the mass of a penny as 3.117 g ± 0.047 g, for example, we are stating that there is only a 5% probability that the penny’s expected mass is less than 3.070 g or more than 3.164 g.
Because a confidence interval is a statement of probability, it allows us to consider comparative questions, such as these: “Are the results for a newly developed method to determine cholesterol in blood significantly different from those obtained using a standard method?” or “Is there a significant variation in the composition of rainwater collected at different sites downwind from a coal-burning utility plant?” In this section we introduce a general approach to the statistical analysis of data. Specific statistical tests are presented in Section 4.6.
The reliability of significance testing recently has received much attention—see Nuzzo, R. “Scientific Method: Statistical Errors,” Nature, 2014, 506, 150–152 for a general discussion of the issues—so it is appropriate to begin this section by noting the need to ensure that our data and our research question are compatible so that we do not read more into a statistical analysis than our data allows; see Leek, J. T.; Peng, R. D. “What is the Question? Science, 2015, 347, 1314-1315 for a use-ul discussion of six common research questions.
In the context of analytical chemistry, significance testing often accompanies an exploratory data analysis (Is there a reason to suspect that there is a difference between these two analytical methods when applied to a common sample?) or an inferential data analysis (Is there a reason to suspect that there is a relationship between these two independent measurements?). A statistically significant result for these types of analytical research questions generally leads to the design of additional experiments better suited to making predictions or to explaining an underlying causal relationship. A significance test is the first step toward building a greater understanding of an analytical problem, not the final answer to that problem.
Significance Testing
Let’s consider the following problem. To determine if a medication is effective in lowering blood glucose concentrations, we collect two sets of blood samples from a patient. We collect one set of samples immediately before we administer the medication, and collect the second set of samples several hours later. After analyzing the samples, we report their respective means and variances. How do we decide if the medication was successful in lowering the patient’s concentration of blood glucose?
One way to answer this question is to construct a normal distribution curve for each sample, and to compare the two curves to each other. Three possible outcomes are shown in Figure 4.5.1 . In Figure 4.5.1 a, there is a complete separation of the two normal distribution curves, which suggests the two samples are significantly different from each other. In Figure 4.5.1 b, the normal distribution curves for the two samples almost completely overlap, which suggests that the difference between the samples is insignificant. Figure 4.5.1 c, however, presents us with a dilemma. Although the means for the two samples seem different, the overlap of their normal distribution curves suggests that a significant number of possible outcomes could belong to either distribution. In this case the best we can do is to make a statement about the probability that the samples are significantly different from each other.
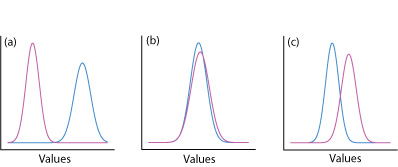
The process by which we determine the probability that there is a significant difference between two samples is called significance testing or hypothesis testing. Before we discuss specific examples we will first establish a general approach to conducting and interpreting a significance test.
Constructing a Significance Test
The purpose of a significance test is to determine whether the difference between two or more results is sufficiently large that it cannot be explained by indeterminate errors. The first step in constructing a significance test is to state the problem as a yes or no question, such as “Is this medication effective at lowering a patient’s blood glucose levels?” A null hypothesis and an alternative hypothesis define the two possible answers to our yes or no question. The null hypothesis, H0, is that indeterminate errors are sufficient to explain any differences between our results. The alternative hypothesis, HA, is that the differences in our results are too great to be explained by random error and that they must be determinate in nature. We test the null hypothesis, which we either retain or reject. If we reject the null hypothesis, then we must accept the alternative hypothesis and conclude that the difference is significant.
Failing to reject a null hypothesis is not the same as accepting it. We retain a null hypothesis because we have insufficient evidence to prove it incorrect. It is impossible to prove that a null hypothesis is true. This is an important point and one that is easy to forget. To appreciate this point let’s return to our sample of 100 pennies in Table 4.4.3. After looking at the data we might propose the following null and alternative hypotheses.
H0: The mass of a circulating U.S. penny is between 2.900 g and 3.200 g
HA: The mass of a circulating U.S. penny may be less than 2.900 g or more than 3.200 g
To test the null hypothesis we find a penny and determine its mass. If the penny’s mass is 2.512 g then we can reject the null hypothesis and accept the alternative hypothesis. Suppose that the penny’s mass is 3.162 g. Although this result increases our confidence in the null hypothesis, it does not prove that the null hypothesis is correct because the next penny we sample might weigh less than 2.900 g or more than 3.200 g.
After we state the null and the alternative hypotheses, the second step is to choose a confidence level for the analysis. The confidence level defines the probability that we will reject the null hypothesis when it is, in fact, true. We can express this as our confidence that we are correct in rejecting the null hypothesis (e.g. 95%), or as the probability that we are incorrect in rejecting the null hypothesis. For the latter, the confidence level is given as \(\alpha\), where
\[\alpha = 1 - \frac {\text{confidence interval (%)}} {100} \label{4.1}\]
For a 95% confidence level, \(\alpha\) is 0.05.
In this textbook we use \(\alpha\) to represent the probability that we incorrectly reject the null hypothesis. In other textbooks this probability is given as p (often read as “p- value”). Although the symbols differ, the meaning is the same.
The third step is to calculate an appropriate test statistic and to compare it to a critical value. The test statistic’s critical value defines a breakpoint between values that lead us to reject or to retain the null hypothesis, which is the fourth, and final, step of a significance test. How we calculate the test statistic depends on what we are comparing, a topic we cover in Section 4.6. The last step is to either retain the null hypothesis, or to reject it and accept the alternative hypothesis.
The four steps for a statistical analysis of data using a significance test:
- Pose a question, and state the null hypothesis, H0, and the alternative hypothesis, HA.
- Choose a confidence level for the statistical analysis.
- Calculate an appropriate test statistic and compare it to a critical value.
- Either retain the null hypothesis, or reject it and accept the alternative hypothesis.
One-Tailed and Two-tailed Significance Tests
Suppose we want to evaluate the accuracy of a new analytical method. We might use the method to analyze a Standard Reference Material that contains a known concentration of analyte, \(\mu\). We analyze the standard several times, obtaining a mean value, \(\overline{X}\), for the analyte’s concentration. Our null hypothesis is that there is no difference between \(\overline{X}\) and \(\mu\)
\[H_0 \text{: } \overline{X} = \mu \nonumber\]
If we conduct the significance test at \(\alpha = 0.05\), then we retain the null hypothesis if a 95% confidence interval around \(\overline{X}\) contains \(\mu\). If the alternative hypothesis is
\[H_\text{A} \text{: } \overline{X} \neq \mu \nonumber\]
then we reject the null hypothesis and accept the alternative hypothesis if \(\mu\) lies in the shaded areas at either end of the sample’s probability distribution curve (Figure 4.5.2 a). Each of the shaded areas accounts for 2.5% of the area under the probability distribution curve, for a total of 5%. This is a two-tailed significance test because we reject the null hypothesis for values of \(\mu\) at either extreme of the sample’s probability distribution curve.
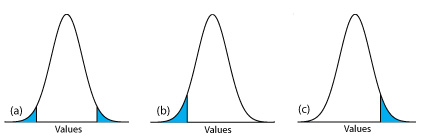
We also can write the alternative hypothesis in two additional ways
\[H_\text{A} \text{: } \overline{X} > \mu \nonumber\]
\[H_\text{A} \text{: } \overline{X} < \mu \nonumber\]
rejecting the null hypothesis if n falls within the shaded areas shown in Figure 4.5.2 b or Figure 4.5.2 c, respectively. In each case the shaded area represents 5% of the area under the probability distribution curve. These are examples of a one-tailed significance test.
For a fixed confidence level, a two-tailed significance test is the more conservative test because rejecting the null hypothesis requires a larger difference between the parameters we are comparing. In most situations we have no particular reason to expect that one parameter must be larger (or must be smaller) than the other parameter. This is the case, for example, when we evaluate the accuracy of a new analytical method. A two-tailed significance test, therefore, usually is the appropriate choice.
We reserve a one-tailed significance test for a situation where we specifically are interested in whether one parameter is larger (or smaller) than the other parameter. For example, a one-tailed significance test is appropriate if we are evaluating a medication’s ability to lower blood glucose levels. In this case we are interested only in whether the glucose levels after we administer the medication are less than the glucose levels before we initiated treatment. If a patient’s blood glucose level is greater after we administer the medication, then we know the answer—the medication did not work—and do not need to conduct a statistical analysis.
Error in Significance Testing
Because a significance test relies on probability, its interpretation is subject to error. In a significance test, a defines the probability of rejecting a null hypothesis that is true. When we conduct a significance test at \(\alpha = 0.05\), there is a 5% probability that we will incorrectly reject the null hypothesis. This is known as a type 1 error, and its risk is always equivalent to \(\alpha\). A type 1 error in a two-tailed or a one-tailed significance tests corresponds to the shaded areas under the probability distribution curves in Figure 4.5.2 .
A second type of error occurs when we retain a null hypothesis even though it is false. This is as a type 2 error, and the probability of its occurrence is \(\beta\). Unfortunately, in most cases we cannot calculate or estimate the value for \(\beta\). The probability of a type 2 error, however, is inversely proportional to the probability of a type 1 error.
Minimizing a type 1 error by decreasing \(\alpha\) increases the likelihood of a type 2 error. When we choose a value for \(\alpha\) we must compromise between these two types of error. Most of the examples in this text use a 95% confidence level (\(\alpha = 0.05\)) because this usually is a reasonable compromise between type 1 and type 2 errors for analytical work. It is not unusual, however, to use a more stringent (e.g. \(\alpha = 0.01\)) or a more lenient (e.g. \(\alpha = 0.10\)) confidence level when the situation calls for it.