
1.3: Functional groups and organic nomenclature
- Page ID
- 106475

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Functional groups are structural units within organic compounds that are defined by specific bonding arrangements between specific atoms. The structure of capsaicin, the compound discussed in the beginning of this chapter, incorporates several functional groups, labeled in the figure below and explained throughout this section.
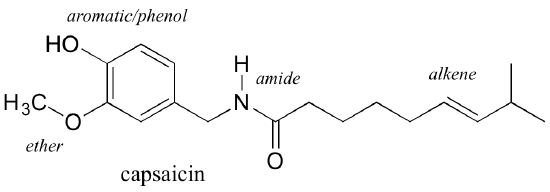
As we progress in our study of organic chemistry, it will become extremely important to be able to quickly recognize the most common functional groups, because they are the key structural elements that define how organic molecules react. For now, we will only worry about drawing and recognizing each functional group, as depicted by Lewis and line structures. Much of the remainder of your study of organic chemistry will be taken up with learning about how the different functional groups behave in organic reactions.
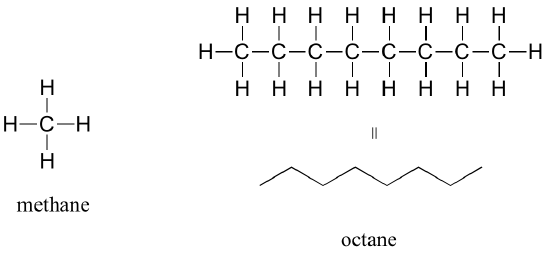
The 'default' in organic chemistry (essentially, the lack of any functional groups) is given the term alkane, characterized by single bonds between carbon and carbon, or between carbon and hydrogen. Methane, CH4, is the natural gas you may burn in your furnace. Octane, C8H18, is a component of gasoline.
Alkenes (sometimes called olefins) have carbon-carbon double bonds, and alkynes have carbon-carbon triple bonds. Ethene, the simplest alkene example, is a gas that serves as a cellular signal in fruits to stimulate ripening. (If you want bananas to ripen quickly, put them in a paper bag along with an apple - the apple emits ethene gas, setting off the ripening process in the bananas). Ethyne, commonly called acetylene, is used as a fuel in welding blow torches.
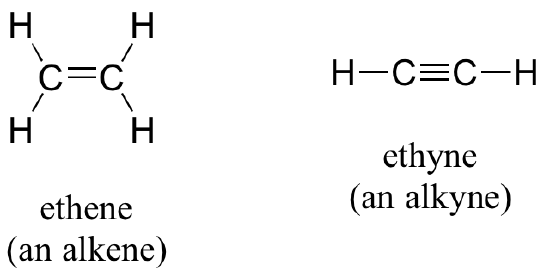
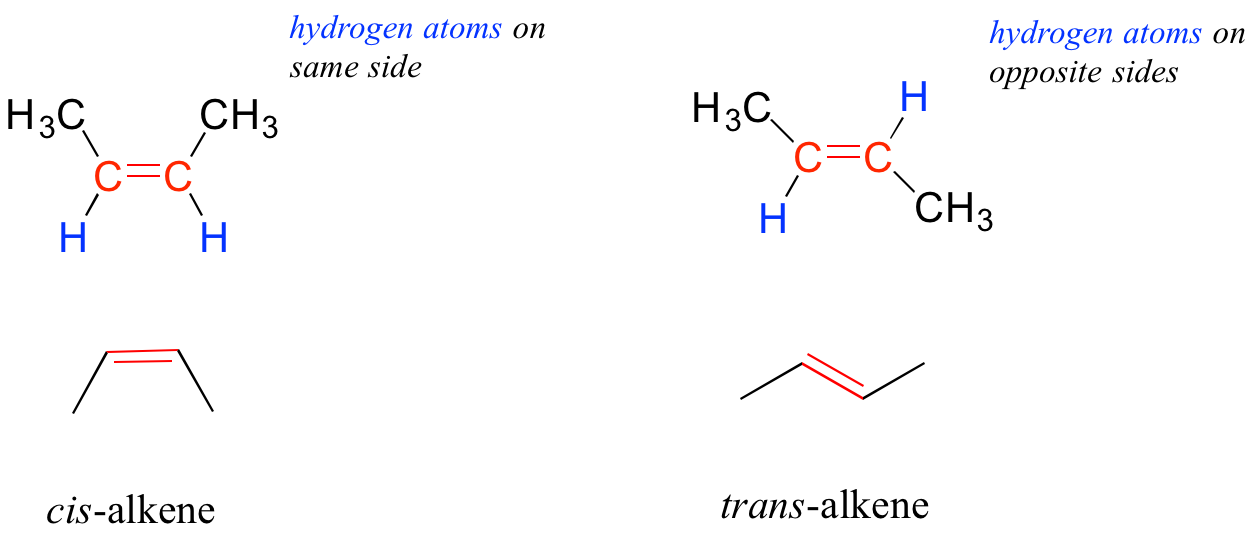
In chapter 2, we will study the nature of the bonding on alkenes and alkynes, and learn that that the bonding in alkenes is trigonal planar in in alkynes is linear. Furthermore, many alkenes can take two geometric forms: cis or trans. The cis and trans forms of a given alkene are different molecules with different physical properties because, as we will learn in chapter 2, there is a very high energy barrier to rotation about a double bond. In the example below, the difference between cis and trans alkenes is readily apparent.
We will have more to say about the subject of cis and trans alkenes in chapter 3, and we will learn much more about the reactivity of alkenes in chapter 14.
Alkanes, alkenes, and alkynes are all classified as hydrocarbons, because they are composed solely of carbon and hydrogen atoms. Alkanes are said to be saturated hydrocarbons, because the carbons are bonded to the maximum possible number of hydrogens - in other words, they are saturated with hydrogen atoms. The double and triple-bonded carbons in alkenes and alkynes have fewer hydrogen atoms bonded to them - they are thus referred to as unsaturated hydrocarbons. As we will see in chapter 15, hydrogen can be added to double and triple bonds, in a type of reaction called 'hydrogenation'.
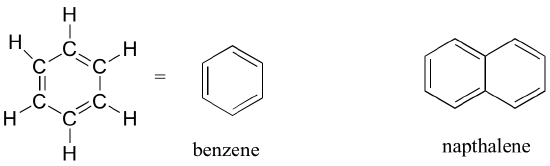
The aromatic group is exemplified by benzene (which used to be a commonly used solvent on the organic lab, but which was shown to be carcinogenic), and naphthalene, a compound with a distinctive 'mothball' smell. Aromatic groups are planar (flat) ring structures, and are widespread in nature. We will learn more about the structure and reactions of aromatic groups in chapters 2 and 14.
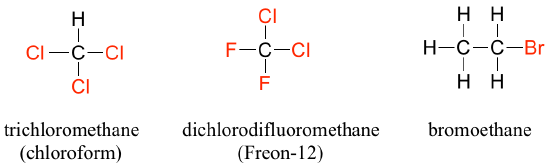
When the carbon of an alkane is bonded to one or more halogens, the group is referred to as a alkyl halide or haloalkane. Chloroform is a useful solvent in the laboratory, and was one of the earlier anesthetic drugs used in surgery. Chlorodifluoromethane was used as a refrigerant and in aerosol sprays until the late twentieth century, but its use was discontinued after it was found to have harmful effects on the ozone layer. Bromoethane is a simple alkyl halide often used in organic synthesis. Alkyl halides groups are quite rare in biomolecules.
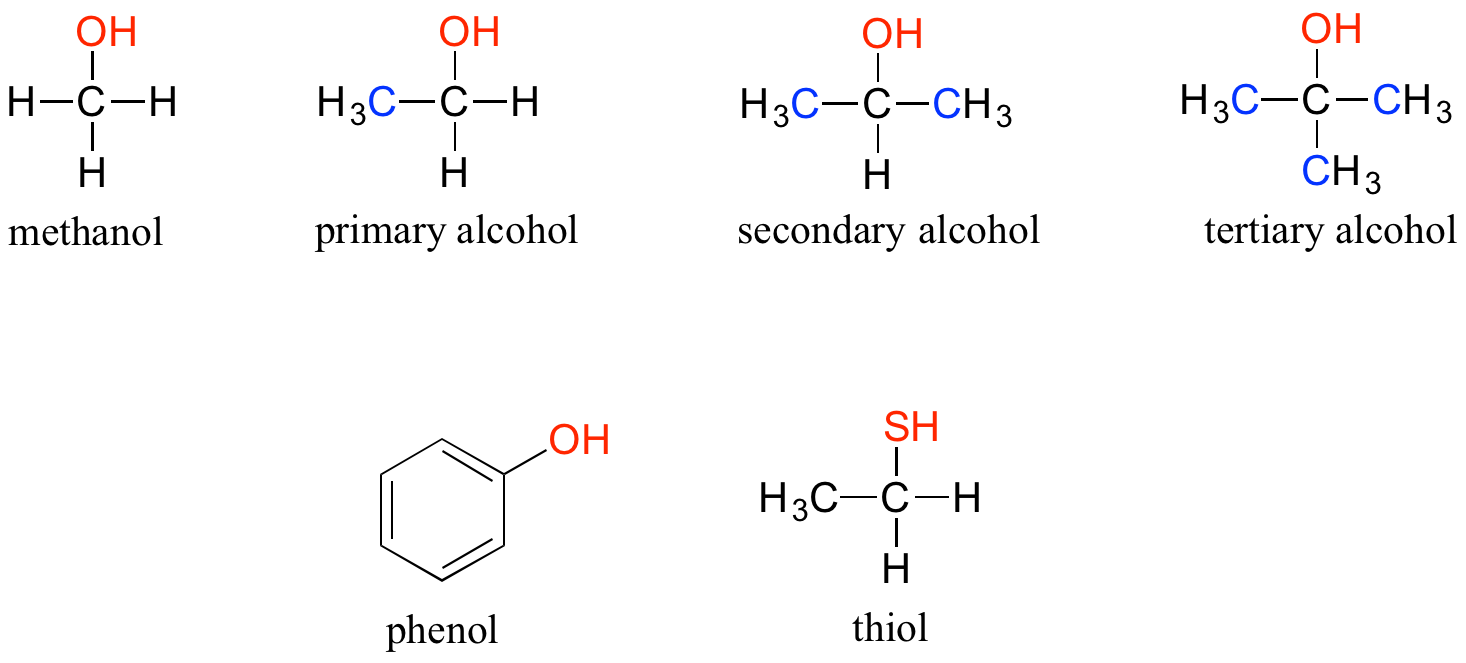
In the alcohol functional group, a carbon is single-bonded to an OH group (the OH group, by itself, is referred to as a hydroxyl). Except for methanol, all alcohols can be classified as primary, secondary, or tertiary. In a primary alcohol, the carbon bonded to the OH group is also bonded to only one other carbon. In a secondary alcohol and tertiary alcohol, the carbon is bonded to two or three other carbons, respectively. When the hydroxyl group is directly attached to an aromatic ring, the resulting group is called a phenol. The sulfur analog of an alcohol is called a thiol (from the Greek thio, for sulfur).
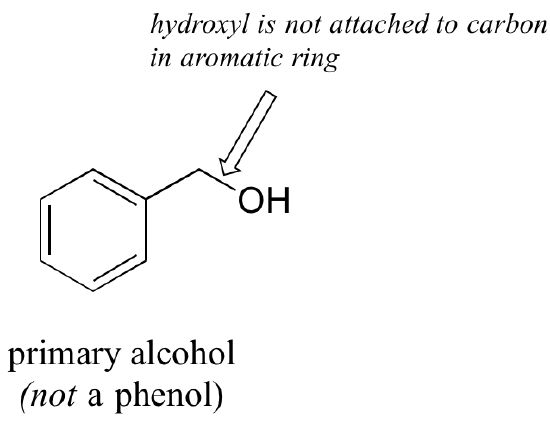
Note that the definition of a phenol states that the hydroxyl oxygen must be directly attached to one of the carbons of the aromatic ring. The compound below, therefore, is not a phenol - it is a primary alcohol.
The distinction is important, because as we will see later, there is a significant difference in the reactivity of alcohols and phenols.
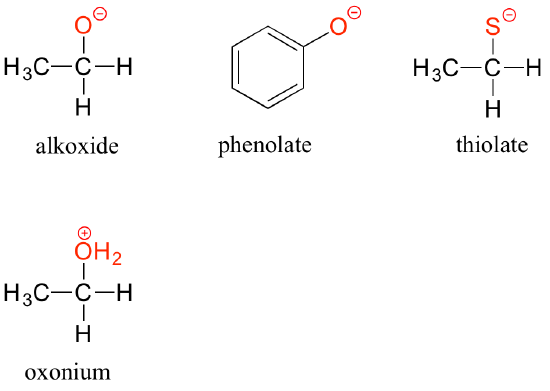
The deprotonated forms of alcohols, phenols, and thiols are called alkoxides, phenolates, and thiolates, respectively. A protonated alcohol is an oxonium ion.
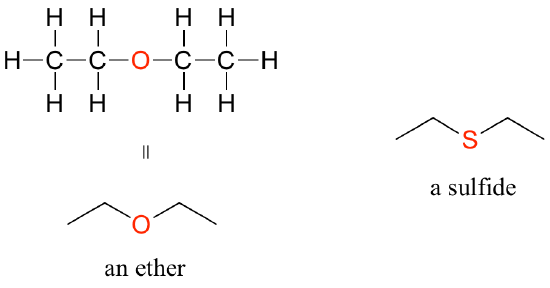
In an ether functional group, a central oxygen is bonded to two carbons. Below is the structure of diethyl ether, a common laboratory solvent and also one of the first compounds to be used as an anesthetic during operations. The sulfur analog of an ether is called a thioether or sulfide.
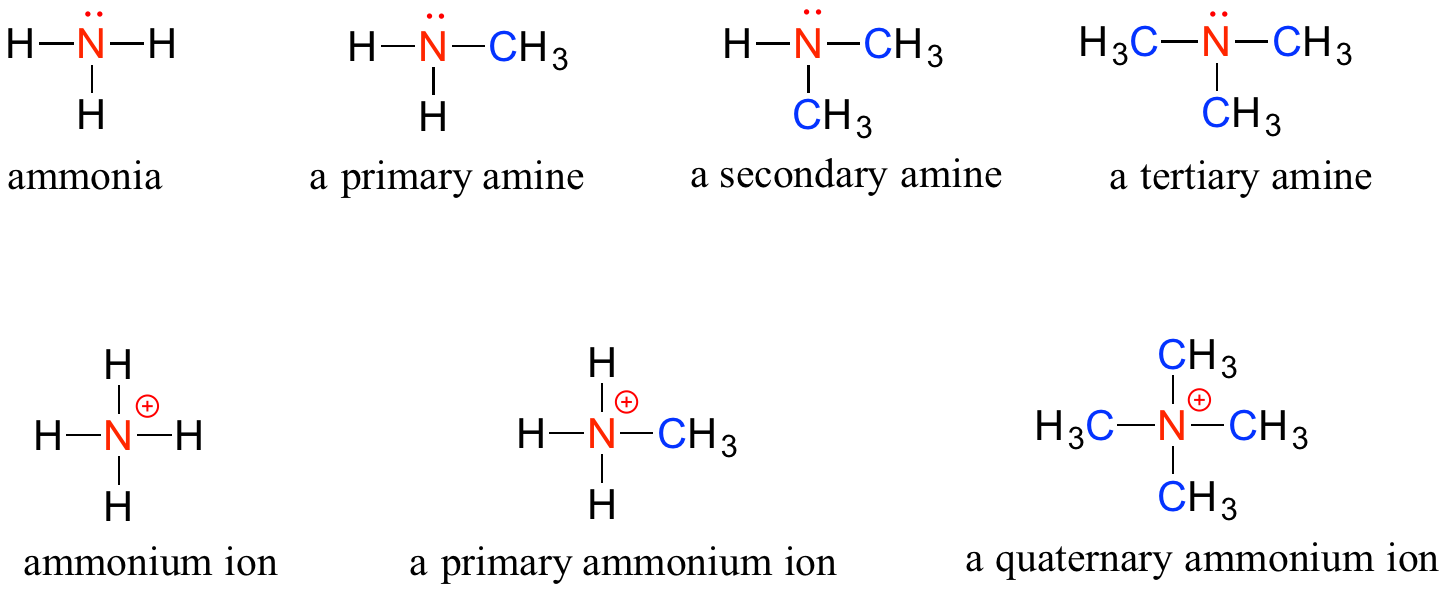
Amines are characterized by nitrogen atoms with single bonds to hydrogen and carbon. Just as there are primary, secondary, and tertiary alcohols, there are primary, secondary, and tertiary amines. Ammonia is a special case with no carbon atoms.
One of the most important properties of amines is that they are basic, and are readily protonated to form ammonium cations. In the case where a nitrogen has four bonds to carbon (which is somewhat unusual in biomolecules), it is called a quaternary ammonium ion.
Do not be confused by how the terms 'primary', 'secondary', and 'tertiary' are applied to alcohols versus amines - the definitions are different. In alcohols, what matters is how many other carbons the alcohol carbon is bonded to, while in amines, what matters is how many carbons the nitrogen is bonded to.
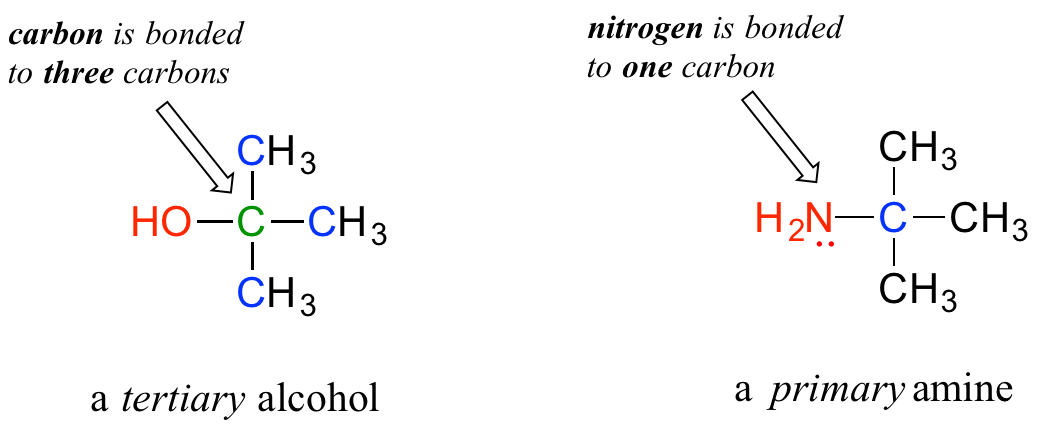
Phosphate and its derivative functional groups are ubiquitous in biomolecules. Phosphate linked to a single organic group is called a phosphate ester; when it has two links to organic groups it is called a phosphate diester. A linkage between two phosphates creates a phosphate anhydride.
Organic phosphates
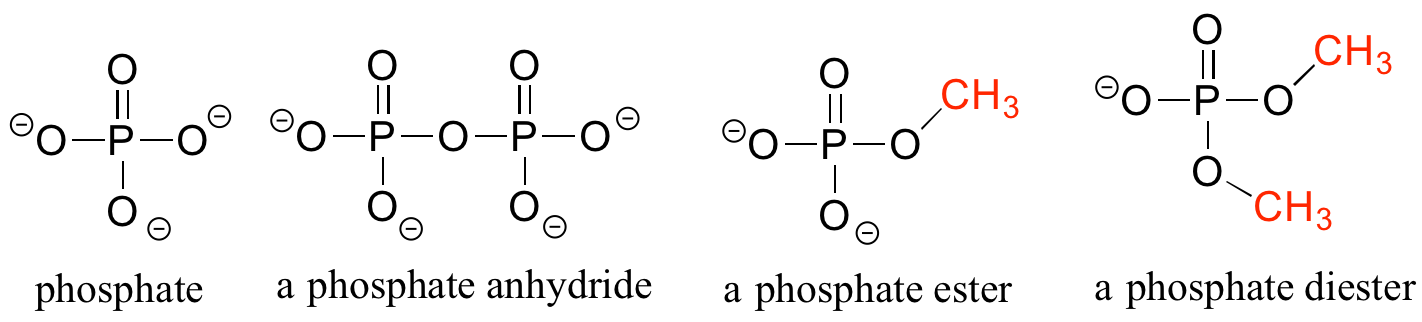
Chapter 9 of this book is devoted to the structure and reactivity of the phosphate group.
There are a number of functional groups that contain a carbon-oxygen double bond, which is commonly referred to as a carbonyl. Ketones and aldehydes are two closely related carbonyl-based functional groups that react in very similar ways. In a ketone, the carbon atom of a carbonyl is bonded to two other carbons. In an aldehyde, the carbonyl carbon is bonded on one side to a hydrogen, and on the other side to a carbon. The exception to this definition is formaldehyde, in which the carbonyl carbon has bonds to two hydrogens.
A group with a carbon-nitrogen double bond is called an imine, or sometimes a Schiff base (in this book we will use the term 'imine'). The chemistry of aldehydes, ketones, and imines will be covered in chapter 10.
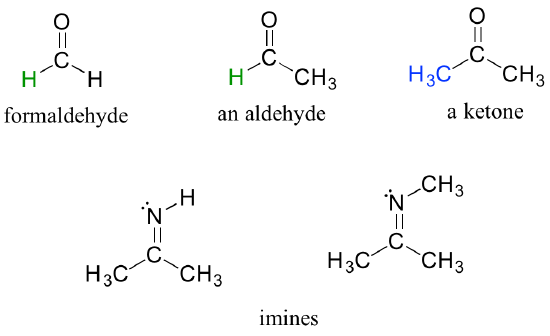
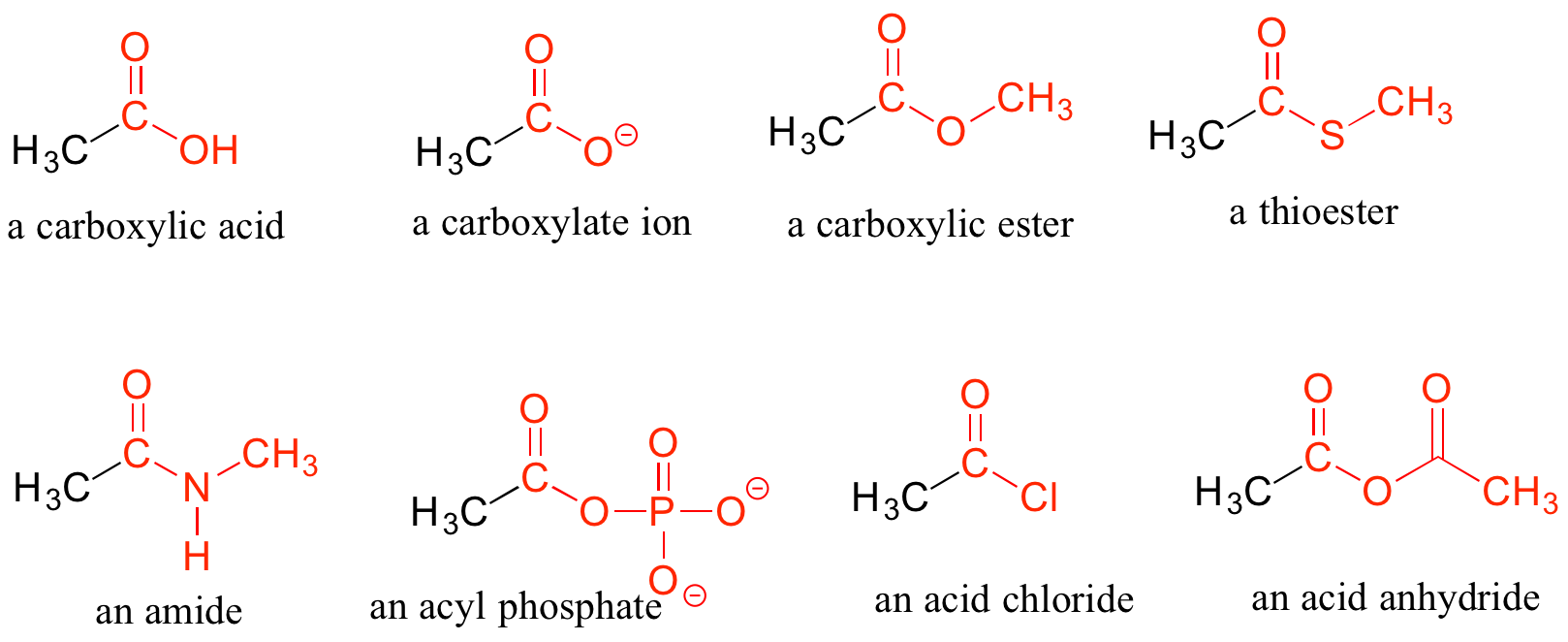
When a carbonyl carbon is bonded on one side to a carbon (or hydrogen) and on the other side to an oxygen, nitrogen, or sulfur, the functional group is considered to be one of the ‘carboxylic acid derivatives’, a designation that describes a set of related functional groups. The eponymous member of this family is the carboxylic acid functional group, in which the carbonyl is bonded to a hydroxyl group. The conjugate base of a carboxylic acid is a carboxylate. Other derivatives are carboxylic esters (usually just called 'esters'), thioesters, amides, acyl phosphates, acid chlorides, and acid anhydrides. With the exception of acid chlorides and acid anhydrides, the carboxylic acid derivatives are very common in biological molecules and/or metabolic pathways, and their structure and reactivity will be discussed in detail in chapter 11.
Finally, a nitrile group is characterized by a carbon triple-bonded to a nitrogen.

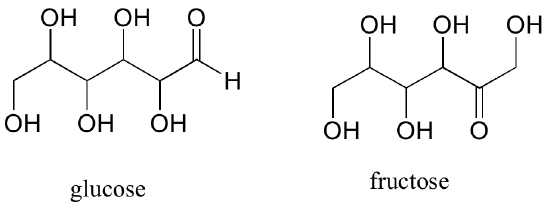
A single compound often contains several functional groups, particularly in biological organic chemistry. The six-carbon sugar molecules glucose and fructose, for example, contain aldehyde and ketone groups, respectively, and both contain five alcohol groups (a compound with several alcohol groups is often referred to as a ‘polyol’).
The hormone testosterone, the amino acid phenylalanine, and the glycolysis metabolite dihydroxyacetone phosphate all contain multiple functional groups, as labeled below.
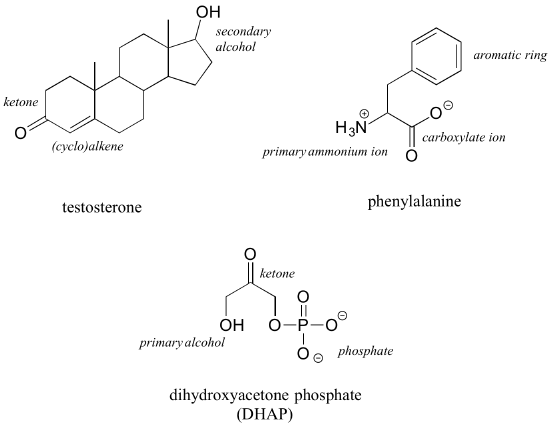
While not in any way a complete list, this section has covered most of the important functional groups that we will encounter in biological organic chemistry. Table 9 in the tables section at the back of this book provides a summary of all of the groups listed in this section, plus a few more that will be introduced later in the text.
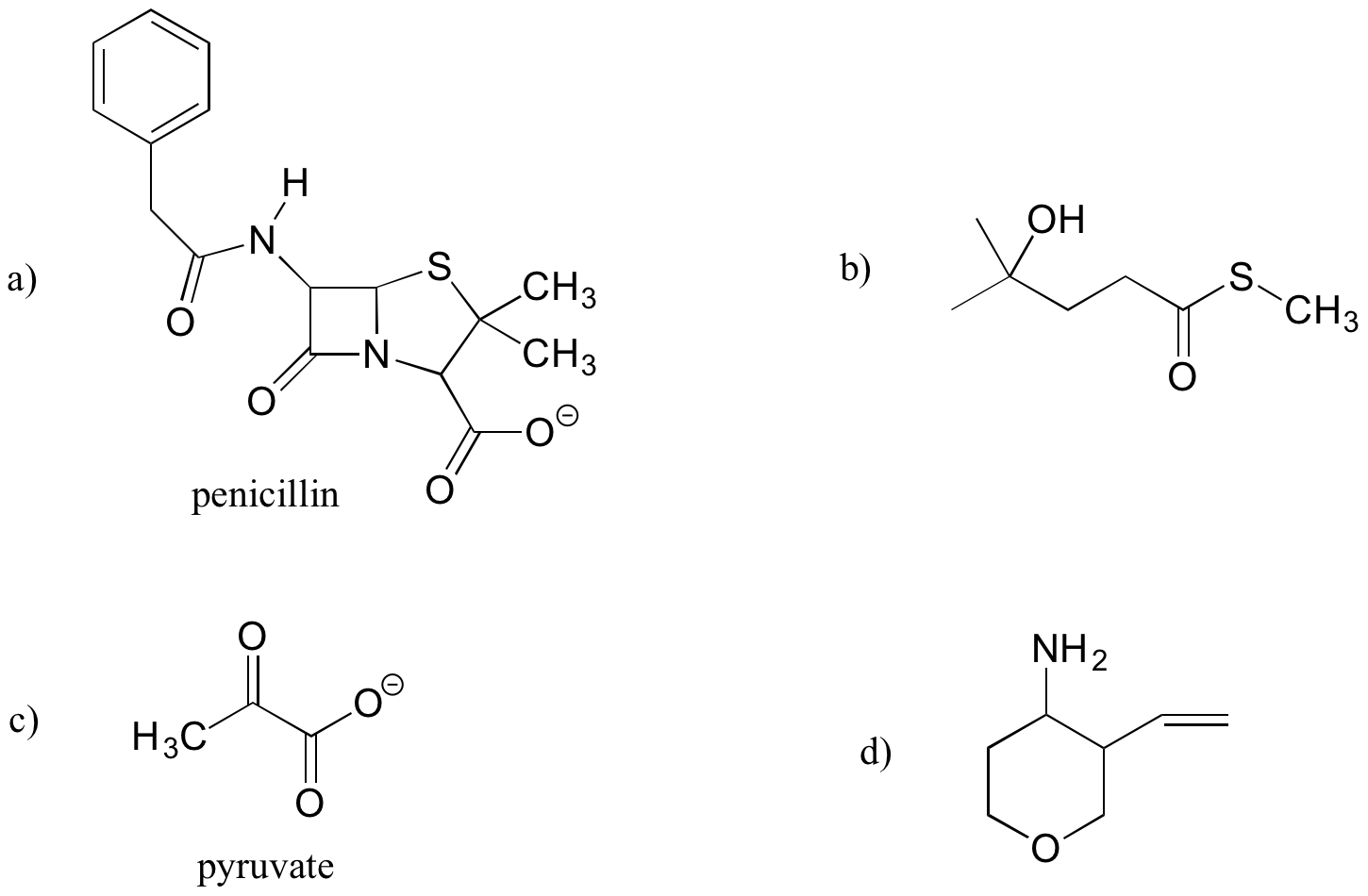
Exercise 1.12
Identify the functional groups (other than alkanes) in the following organic compounds. State whether alcohols and amines are primary, secondary, or tertiary.
Solutions to exercises
Exercise 1.13
Draw one example each of compounds fitting the descriptions below, using line structures. Be sure to designate the location of all non-zero formal charges. All atoms should have complete octets (phosphorus may exceed the octet rule). There are many possible correct answers for these, so be sure to check your structures with your instructor or tutor.
a) a compound with molecular formula C6H11NO that includes alkene, secondary amine, and primary alcohol functional groups
b) an ion with molecular formula C3H5O6P 2- that includes aldehyde, secondary alcohol, and phosphate functional groups.
c) A compound with molecular formula C6H9NO that has an amide functional group, and does not have an alkene group.
Naming organic compounds
A system has been devised by the International Union of Pure and Applied Chemistry (IUPAC, usually pronounced eye-you-pack) for naming organic compounds. While the IUPAC system is convenient for naming relatively small, simple organic compounds, it is not generally used in the naming of biomolecules, which tend to be quite large and complex. It is, however, a good idea (even for biologists) to become familiar with the basic structure of the IUPAC system, and be able to draw simple structures based on IUPAC names.
Naming an organic compound usually begins with identify what is referred to as the 'parent chain', which is the longest straight chain of carbon atoms. We’ll start with the simplest straight chain alkane structures. CH4 is called methane, and C2H6 ethane. The table below continues with the names of longer straight-chain alkanes: be sure to commit these to memory, as they are the basis for the rest of the IUPAC nomenclature system (and are widely used in naming biomolecules as well).
1 carbon: methane
2 carbons: ethane
3 carbons: propane
4 carbons: butane
5 carbons: pentane
6 carbons: hexane
7 carbons: heptane
8 carbons: octane
9 carbons: nonane
10 carbons: decane
Substituents branching from the main parent chain are located by a carbon number, with the lowest possible numbers being used (for example, notice in the example below that the compound on the left is named 1-chlorobutane, not 4-chlorobutane). When the substituents are small alkyl groups, the terms methyl, ethyl, and propyl are used.

Other common names for hydrocarbon substituent groups are isopropyl, tert-butyl and phenyl.
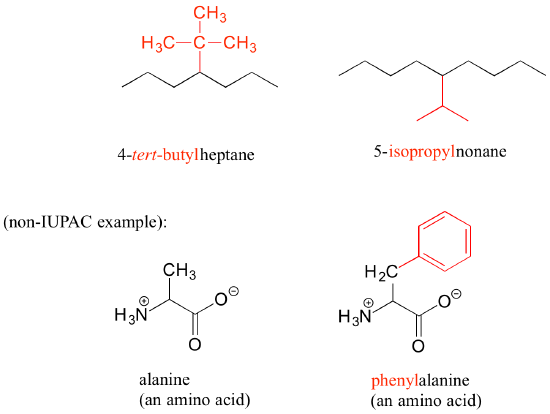
Notice in the example below, an ‘ethyl group’ (in blue) is not treated as a substituent, rather it is included as part of the parent chain, and the methyl group is treated as a substituent. The IUPAC name for straight-chain hydrocarbons is always based on the longest possible parent chain, which in this case is four carbons, not three.

Cyclic alkanes are called cyclopropane, cyclobutane, cyclopentane, cyclohexane, and so on:

In the case of multiple substituents, the prefixes di, tri, and tetra are used.
Functional groups have characteristic suffixes. Alcohols, for example, have ‘ol’ appended to the parent chain name, along with a number designating the location of the hydroxyl group. Ketones are designated by ‘one’.
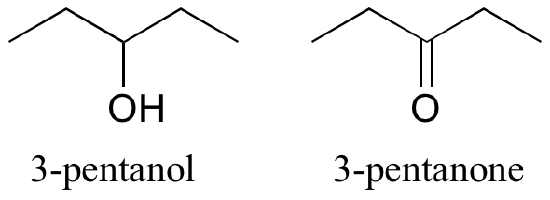
Alkenes are designated with an 'ene' ending, and when necessary the location and geometry of the double bond are indicated. Compounds with multiple double bonds are called dienes, trienes, etc.

Some groups can only be present on a terminal carbon, and thus a locating number is not necessary: aldehydes end in ‘al’, carboxylic acids in ‘oic acid’, and carboxylates in ‘oate’.

Ethers and sulfides are designated by naming the two groups on either side of the oxygen or sulfur.

If an amide has an unsubstituted –NH2 group, the suffix is simply ‘amide’. In the case of a substituted amide, the group attached to the amide nitrogen is named first, along with the letter ‘N’ to clarify where this group is located. Note that the structures below are both based on a three-carbon (propan) parent chain.

For esters, the suffix is 'oate'. The group attached to the oxygen is named first.
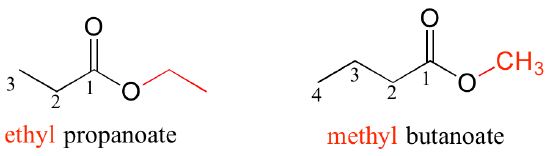
All of the examples we have seen so far have been simple in the sense that only one functional group was present on each molecule. There are of course many more rules in the IUPAC system, and as you can imagine, the IUPAC naming of larger molecules with multiple functional groups, ring structures, and substituents can get very unwieldy very quickly. The illicit drug cocaine, for example, has the IUPAC name 'methyl (1R,2R,3S,5S)-3-(benzoyloxy)-8-methyl-8-azabicyclo[3.2.1] octane-2-carboxylate' (this name includes designations for stereochemistry, which is a structural issue that we will not tackle until chapter 3).
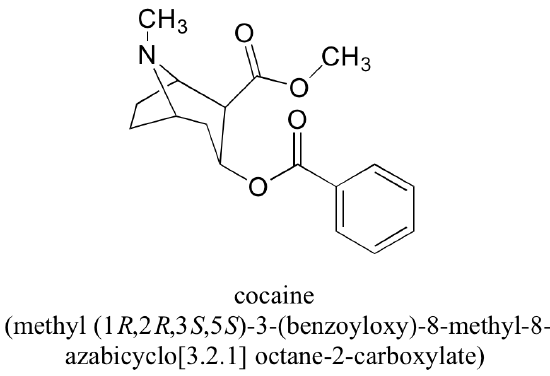
You can see why the IUPAC system is not used very much in biological organic chemistry - the molecules are just too big and complex. A further complication is that, even outside of a biological context, many simple organic molecules are known almost universally by their ‘common’, rather than IUPAC names. The compounds acetic acid, chloroform, and acetone are only a few examples.
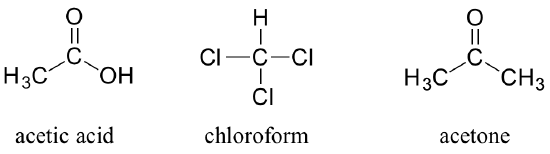
In biochemistry, nonsystematic names (like 'cocaine', 'capsaicin', 'pyruvate' or 'ascorbic acid') are usually used, and when systematic nomenclature is employed it is often specific to the class of molecule in question: different systems have evolved, for example, for fats and for carbohydrates. We will not focus very intensively in this text on IUPAC nomenclature or any other nomenclature system, but if you undertake a more advanced study in organic or biological chemistry you may be expected to learn one or more naming systems in some detail.
Exercise 1.14
Give IUPAC names for acetic acid, chloroform, and acetone.
Exercise 1.15
Draw line structures of the following compounds, based on what you have learned about the IUPAC nomenclature system:
- methylcyclohexane
- 5-methyl-1-hexanol
- 2-methyl-2-butene
- 5-chloropentanal
- 2,2-dimethylcyclohexanone
- 4-penteneoic acid
- N-ethyl-N-cyclopentylbutanamide
Solutions to exercises
Drawing abbreviated organic structures
Often when drawing organic structures, chemists find it convenient to use the letter 'R' to designate part of a molecule outside of the region of interest. If we just want to refer in general to a functional group without drawing a specific molecule, for example, we can use 'R groups' to focus attention on the group of interest:
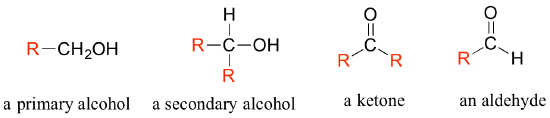
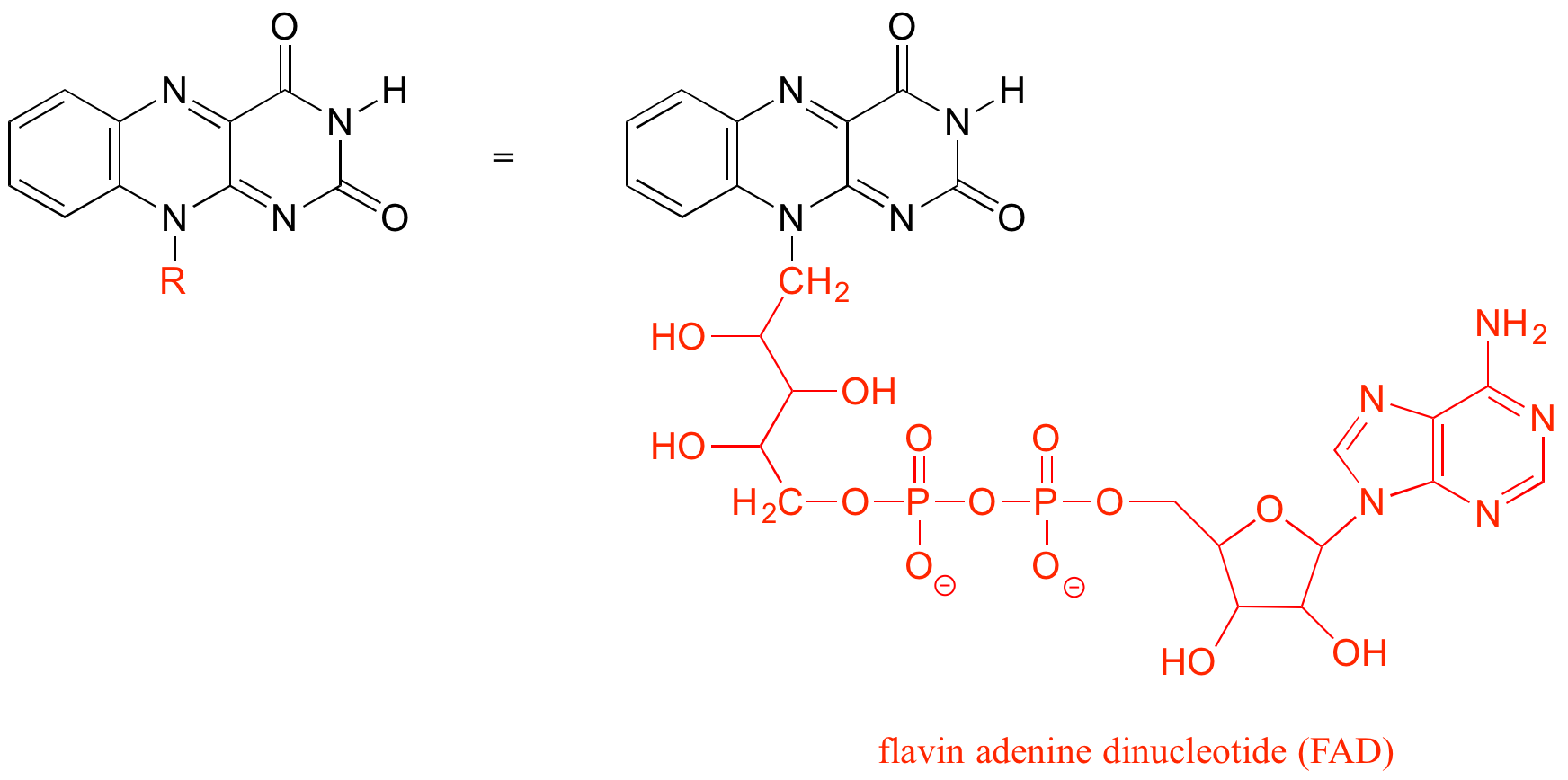
The 'R' group is a convenient way to abbreviate the structures of large biological molecules, especially when we are interested in something that is occurring specifically at one location on the molecule. For example, in chapter 15 when we look at biochemical oxidation-reduction reactions involving the flavin molecule, we will abbreviate a large part of the flavin structure which does not change at all in the reactions of interest:
As an alternative, we can use a 'break' symbol to indicate that we are looking at a small piece or section of a larger molecule. This is used commonly in the context of drawing groups on large polymers such as proteins or DNA.

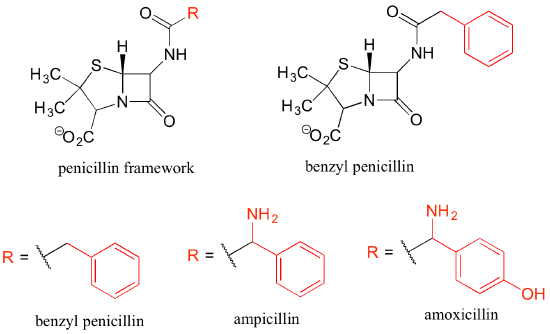
Finally, 'R' groups can be used to concisely illustrate a series of related compounds, such as the family of penicillin-based antibiotics.
Using abbreviations appropriately is a very important skill to develop when studying organic chemistry in a biological context, because although many biomolecules are very large and complex (and take forever to draw!), usually we are focusing on just one small part of the molecule where a change is taking place.
As a rule, you should never abbreviate any atom involved in a bond-breaking or bond-forming event that is being illustrated: only abbreviate that part of the molecule which is not involved in the reaction of interest.
For example, carbon #2 in the reactant/product below most definitely is involved in bonding changes, and therefore should not be included in the 'R' group.
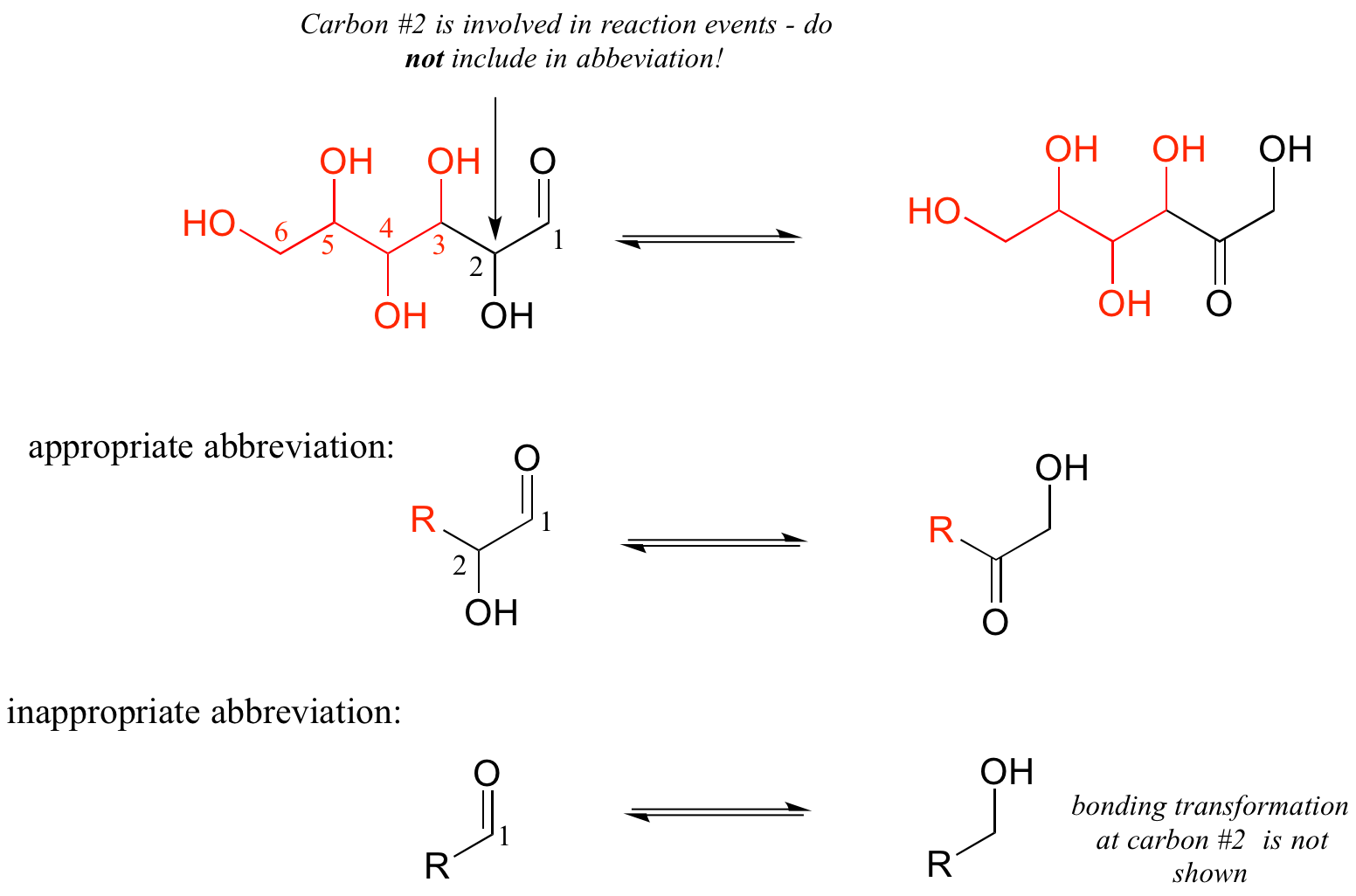
If you are unsure whether to draw out part of a structure or abbreviate it, the safest thing to do is to draw it out.
a) If you intend to draw out the chemical details of a reaction in which the methyl ester functional group of cocaine (see earlier figure) was converted to a carboxylate plus methanol, what would be an appropriate abbreviation to use for the cocaine structure (assuming that you only wanted to discuss the chemistry specifically occurring at the ester group)?
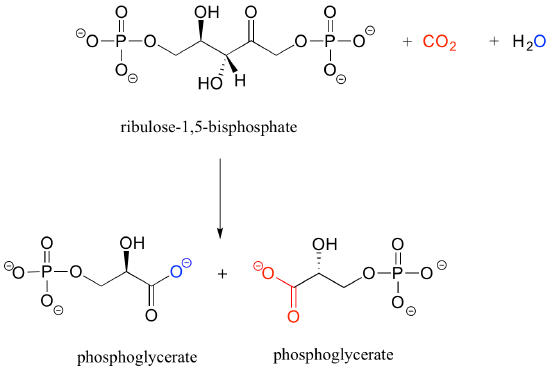
b) Below is the (somewhat complicated) reaction catalyzed by an enzyme known as 'Rubisco', by which plants 'fix' carbon dioxide. Carbon dioxide and the oxygen of water are colored red and blue respectively to help you see where those atoms are incorporated into the products. Propose an appropriate abbreviation for the starting compound (ribulose 1,5-bisphosphate), using two different 'R' groups, R1 and R2.
Solutions to exercises
Contributors and Attributions
Organic Chemistry With a Biological Emphasis by Tim Soderberg (University of Minnesota, Morris)