
4.E: Evaluating Analytical Data (Exercises)
- Page ID
- 70646
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Many of the problems that follow require access to statistical tables. For your convenience, here are hyperlinks to the appendices containing these tables.
Appendix 3: Single-Sided Normal Distribution
Appendix 4: Critical Values for the t-Test
Appendix 5: Critical Values for the F-Test
Appendix 6: Critical Values for Dixon’s Q-Test
Appendix 7: Critical Values for Grubb’s Test
1. The following masses were recorded for 12 different U.S. quarters (all given in grams):
|
5.683 |
5.549 |
5.548 |
5.552 |
Report the mean, median, range, standard deviation and variance for this data.
2. A determination of acetaminophen in 10 separate tablets of Excedrin Extra Strength Pain Reliever gives the following results (in mg).16
| 224.3 261.7 |
240.4 229.4 |
246.3 255.5 |
239.4 235.5 |
253.1 249.7 |
(a) Report the mean, median, range, standard deviation and variance for this data. (b) Assuming that X and s2 are good approximations for μ and σ2, and that the population is normally distributed, what percentage of tablets contain more than the standard amount of 250 mg acetaminophen per tablet?
3. Salem and Galan developed a new method for determining the amount of morphine hydrochloride in tablets.17 An analysis of tablets with different nominal dosages gave the following results (in mg/tablet).
|
100-mg tablets 99.17 |
60-mg tablets 54.21 |
30-mg tablets 28.51 |
10-mg tablets 9.06 |
(a) For each dosage, calculate the mean and standard deviation for the mg of morphine hydrochloride per tablet. (b) For each dosage level, assuming that X and s2 are good approximations for μ and σ2, and that the population is normally distributed, what percentage of tablets contain more than the nominal amount of morphine hydrochloride per tablet?
4. Daskalakis and co-workers evaluated several procedures for digesting oyster and mussel tissue prior to analyzing them for silver.18 To evaluate the procedures they spiked samples with known amounts of silver and analyzed the samples to determine the amount of silver, reporting results as the percentage of added silver found in the analysis. A procedure was judged acceptable is the spike recoveries fell within the range 100±15%. The spike recoveries for one method are shown here.
|
106% |
108% 93% |
92% |
99% 104% |
Assuming a normal distribution for the spike recoveries, what is the probability that any single spike recovery will be within the accepted range?
5. The formula weight (FW) of a gas can be determined using the following form of the ideal gas law
\[FW = \dfrac{g\ce{R}T}{PV}\]
where g is the mass in grams, R is the gas constant, T is the temperature in Kelvin, P is the pressure in atmospheres, and V is the volume in liters.
In a typical analysis the following data are obtained (with estimated uncertainties in parentheses)
\[\begin{align}
&\mathrm{g = 0.118\: g\: (± 0.002\: g)}\\
&\mathrm{R = 0.082056\: L\: atm\: mol^{–1}\: K^{–1}\: (± 0.000001\: L\: atm\: mol^{–1}\: K^{–1})}\\
&\mathrm{T = 298.2\: K\: (± 0.1\: K)}\\
&\mathrm{P = 0.724\: atm\: (± 0.005\: atm)}\\
&\mathrm{V = 0.250\: L\: (± 0.005\: L)}
\end{align}\]
(a) What is the compound’s formula weight and its estimated uncertainty? (b) To which variable(s) should you direct your attention if you wish to improve the uncertainty in the compound’s molecular weight?
6. To prepare a standard solution of Mn2+ a 0.250 g sample of Mn is dissolved in 10 mL of concentrated HNO3 (measured with a graduated cylinder). The resulting solution is quantitatively transferred to a 100-mL volumetric flask and diluted to volume with distilled water. A 10 mL aliquot of the solution is pipeted into a 500-mL volumetric flask and diluted to volume. (a) Express the concentration of Mn in mg/L, and estimate its uncertainty using a propagation of uncertainty. (b) Can you improve the concentration’s uncertainty by using a pipet to measure the HNO3, instead of a graduated cylinder?
7. The mass of a hygroscopic compound is measured using the technique of weighing by difference. In this technique the compound is placed in a sealed container and weighed. A portion of the compound is removed, and the container and the remaining material are reweighed. The difference between the two masses gives the sample’s mass. A solution of a hygroscopic compound with a gram formula weight of 121.34 g/mol (±0.01 g/mol) was prepared in the following manner. A sample of the compound and its container has a mass of 23.5811 grams. A portion of the compound was transferred to a 100-mL volumetric flask and diluted to volume. The mass of the compound and container after the transfer is 22.1559 grams. Calculate the compound’s molarity and estimate its uncertainty by a propagation of uncertainty.
8. Show using a propagation of uncertainty that the standard error of the mean for n determinations is s / √n.
9. Beginning with equation 4.17 and equation 4.18, use a propagation of uncertainty to derive equation 4.19.
10. What is the smallest mass that we can measure on an analytical balance that has a tolerance of ±0.1 mg, if the relative error must be less than 0.1%?
11. Which of the following is the best way to dispense 100.0 mL of a reagent: (a) use a 50‑mL pipet twice; (b) use a 25-mL pipet four times; or (c) use a 10-mL pipet ten times?
12. You can dilute a solution by a factor of 200 using readily available pipets (1-mL to 100-mL) and volumetric flasks (10-mL to 1000-mL) in either one step, two steps, or three steps. Limiting yourself to the glassware in Table 4.2, determine the proper combination of glassware to accomplish each dilution, and rank them in order of their most probable uncertainties.
13. Explain why changing all values in a data set by a constant amount will change X but will have no effect on s.
14. Obtain a sample of a metal from your instructor and determine its density by one or both of the following methods:
Method A: Determine the sample’s mass with a balance. Calculate the sample’s volume using appropriate linear dimensions.
Method B: Determine the sample’s mass with a balance. Calculate the sample’s volume by measuring the amount of water that it displaces. This can be done by adding water to a graduated cylinder, reading the volume, adding the sample, and reading the new volume. The difference in volumes is equal to the sample’s volume.
Determine the density at least 5 times. (a) Report the mean, the standard deviation, and the 95% confidence interval for your results. (b) Find the accepted value for the metal’s density and determine the absolute and relative error for your determination of the metal’s density. (c) Use a propagation of uncertainty to determine the uncertainty for your method of analysis. Is the result of this calculation consistent with your experimental results? If not, suggest some possible reasons for this disagreement.
15. How many carbon atoms must a molecule have if the mean number of 13C atoms per molecule is 1.00? What percentage of such molecules will have no atoms of 13C?
16. In Example 4.10 we determined the probability that a molecule of cholesterol, C27H44O, had no atoms of 13C. (a) Calculate the probability that a molecule of cholesterol, has 1 atom of 13C. (b) What is the probability that a molecule of cholesterol will have two or more atoms of 13C?
17. Berglund and Wichardt investigated the quantitative determination of Cr in high-alloy steels using a potentiometric titration of Cr(VI)19.
Before the titration, samples of the steel were dissolved in acid and the chromium oxidized to Cr(VI) using peroxydisulfate. Shown here are the results ( as %w/w Cr) for the analysis of a reference steel.
| 16.968 16.887 |
16.922 16.977 |
16.840 16.857 |
16.883 16.728 |
Calculate the mean, the standard deviation, and the 95% confidence interval about the mean. What does this confidence interval mean?
18. Ketkar and co-workers developed an analytical method for determining trace levels of atmospheric gases.20 An analysis of a sample containing 40.0 parts per thousand (ppt) 2‑chloroethylsulfide yielded the following results
| 43.3 37.8 42.1 |
34.8 34.4 33.6 |
31.9 31.9 35.3 |
(a) Determine whether there is a significant difference between the experimental mean and the expected value at α = 0.05. (b) As part of this study a reagent blank was analyzed 12 times, giving a mean of 0.16 ppt and a standard deviation of 1.20 ppt. What are the IUPAC detection limit, the limit of identification, and limit of quantitation for this method assuming α = 0.05?
19. To test a spectrophotometer’s accuracy a solution of 60.06 ppm K2Cr2O7 in 5.0 mM H2SO4 is prepared and analyzed. This solution has an expected absorbance of 0.640 at 350.0 nm in a 1.0-cm cell when using 5.0 mM H2SO4 as a reagent blank. Several aliquots of the solution produce the following absorbance values.
0.639 0.638 0.640 0.639 0.640 0.639 0.638
Determine whether there is a significant difference between the experimental mean and the expected value at α = 0.01.
20. Monna and co-workers used radioactive isotopes to date sediments from lakes and estuaries.21 To verify this method they analyzed a 208Po standard known to have an activity of 77.5 decays/min, obtaining the following results.
| 77.09 78.03 |
75.37 74.96 |
72.42 77.54 |
76.84 76.09 |
77.84 81.12 |
76.69 75.75 |
Determine whether there is a significant difference between the mean and the expected value at α = 0.05.
21. A 2.6540-g sample of an iron ore, known to be 53.51% w/w Fe, is dissolved in a small portion of concentrated HCl and diluted to volume in a 250-mL volumetric flask. A spectrophotometric determination of the concentration of Fe in this solution yields results of 5840, 5770, 5650, and 5660 ppm. Determine whether there is a significant difference between the experimental mean and the expected value at α = 0.05.
22. Horvat and co-workers used atomic absorption spectroscopy to determine the concentration of Hg in coal fly ash.22 Of particular interest to the authors was developing an appropriate procedure for digesting samples and releasing the Hg for analysis. As part of their study they tested several reagents for digesting samples. Results obtained using HNO3 and using a 1 + 3 mixture of HNO3 and HCl are shown here. All concentrations are given as ng Hg/g sample.
HNO3 161 165 160 167 166
1+3 HNO3–HCl 159 145 140 147 143 156
Determine whether there is a significant difference between these methods at α = 0.05.
23. Lord Rayleigh, John William Strutt (1842-1919), was one of the most well known scientists of the late nineteenth and early twentieth centuries, publishing over 440 papers and receiving the Nobel Prize in 1904 for the discovery of argon. An important turning point in Rayleigh’s discovery of Ar was his experimental measurements of the density of N2. Rayleigh approached this experiment in two ways: first by taking atmospheric air and removing all O2 and H2; and second, by chemically producing N2 by decomposing nitrogen containing compounds (NO, N2O, and NH4NO3) and again removing all O2 and H2. Following are his results for the density of N2, published in Proc. Roy. Soc. 1894, LV, 340 (publication 210) (all values are for grams of gas at an equivalent volume, pressure, and temperature).23
|
Atmospheric Chemical |
2.310 17 2.301 43 |
2.309 86 2.298 90 |
2.310 10 2.298 16 |
2.310 01 2.301 82 |
Explain why this data led Rayleigh to look for, and discover Ar.
24. Gács and Ferraroli reported a method for monitoring the concentration of SO2 in air.24 They compared their method to the standard method by analyzing urban air samples collected from a single location. Samples were collected by drawing air through a collection solution for 6 min.
Shown here is a summary of their results with SO2 concentrations reported in μL/m3.
|
standard new |
21.62 21.54 |
22.20 20.51 |
24.27 22.31 |
23.54 21.30 |
Using an appropriate statistical test determine whether there is any significant difference between the standard method and the new method at α = 0.05.
25. One way to check the accuracy of a spectrophotometer is to measure absorbencies for a series of standard dichromate solutions obtained from the National Institute of Standards and Technology. Absorbencies are measured at 257 nm and compared to the accepted values. The results obtained when testing a newly purchased spectrophotometer are shown here. Determine if the tested spectrophotometer is accurate at α = 0.05.
|
Standard 1 2 3 4 5 |
Measured Absorbance 0.2872 0.5773 0.8674 1.1623 1.4559 |
Expected Absorbance 0.2871 0.5760 0.8677 1.1608 1.4565 |
26. Maskarinec and co-workers investigated the stability of volatile organics in environmental water samples.25 Of particular interest was establishing proper conditions for maintaining the sample’s integrity between its collection and analysis. Two preservatives were investigated—ascorbic acid and sodium bisulfate—and maximum holding times were determined for a number of volatile organics and water matrices. The following table shows results (in days) for the holding time of nine organic compounds in surface water.
|
methylene chloride carbon disulfide trichloroethane benzene 1,1,2-trichloroethane 1,1,2,2-tetrachlorethane tetrachloroethene toluene chlorobenzene |
Ascorbic Acid 77 23 52 62 57 33 41 32 36 |
Sodium Bisulfate 62 54 51 42 53 85 63 94 86 |
Determine whether there is a significant difference in the effectiveness of the two preservatives at α = 0.10.
27. Using X-ray diffraction, Karstang and Kvalhein reported a new method for determining the weight percent of kalonite in complex clay minerals using X-ray diffraction.26 To test the method, nine samples containing known amounts of kalonite were prepared and analyzed. The results (as % w/w kalonite) are shown here.
Actual: 5.0 10.0 20.0 40.0 50.0 60.0 80.0 90.0 95.0
Found: 6.8 11.7 19.8 40.5 53.6 61.7 78.9 91.7 94.7
Evaluate the accuracy of the method at α = 0.05.
28. Mizutani, Yabuki and Asai developed an electrochemical method for analyzing l-malate.27 As part of their study they analyzed a series of beverages using both their method and a standard spectrophotometric procedure based on a clinical kit purchased from Boerhinger Scientific. The following table summarizes their results. All values are in ppm.
|
Sample Apple juice 1 |
Electrode 34.0 |
Spectrophotometric 33.4 |
Determine whether there is a significant difference between the methods at α = 0.05.
29. Alexiev and colleagues describe an improved photometric method for determining Fe3+ based on its ability to catalyze the oxidation of sulphanilic acid by KIO4.28 As part of their study the concentration of Fe3+ in human serum samples was determined by the improved method and the standard method. The results, with concentrations in μmol/L, are shown in the following table.
|
Sample 1 |
Improved Method 8.25 |
Standard Method 8.06 |
Determine whether there is a significant difference between the two methods at α = 0.05.
30. Ten laboratories were asked to determine an analyte’s concentration in three standard test samples. Following are the results, in μg/mL.29
|
Laboratory 1 |
Sample 1 22.6 |
Sample 2 13.6 |
Sample 3 16.0 |
Determine if there are any potential outliers in Sample 1, Sample 2 or Sample 3 at a significance level of α = 0.05. Use all three methods—Dixon’s Q-test, Grubb’s test, and Chauvenet’s criterion—and compare the results to each other.
31. When copper metal and powdered sulfur are placed in a crucible and ignited, the product is a sulfide with an empirical formula of CuxS. The value of x can be determined by weighing the Cu and S before ignition, and finding the mass of CuxS when the reaction is complete (any excess sulfur leaves as SO2). The following table shows the Cu/S ratios from 62 such experiments.
1.764 1.838 1.865 1.866 1.872 1.877
1.890 1.891 1.891 1.897 1.899 1.900
1.906 1.908 1.910 1.911 1.916 1.919
1.920 1.922 1.927 1.931 1.935 1.936
1.936 1.937 1.939 1.939 1.940 1.941
1.941 1.942 1.943 1.948 1.953 1.955
1.957 1.957 1.957 1.959 1.962 1.963
1.963 1.963 1.966 1.968 1.969 1.973
1.975 1.976 1.977 1.981 1.981 1.988
1.993 1.993 1.995 1.995 1.995 2.017
2.029 2.042
(a) Calculate the mean and standard deviation for this data. (b) Construct a histogram for this data. From a visual inspection of your histogram, does the data appear to be normally distributed? (c) In a normally distributed population 68.26% of all members lie within the range μ ± 1σ. What percentage of the data lies within the range ± 1s? Does this support your answer to the previous question? (d) Assuming that X and s2 are good approximations for μ and σ2, what percentage of all experimentally determined Cu/S ratios will be greater than 2? How does this compare with the experimental data? Does this support your conclusion about whether the data is normally distributed? (e) It has been reported that this method of preparing copper sulfide results in a non-stoichiometric compound with a Cu/S ratio of less than 2. Determine if the mean value for this data is significantly less than 2 at a significance level of α = 0.01.
32. Real-time quantitative PCR is an analytical method for determining trace amounts of DNA. During the analysis, each cycle doubles the amount of DNA. A probe species that fluoresces in the presence of DNA is added to the reaction mixture and the increase in fluorescence is monitored during the cycling. The cycle threshold, Ct, is the cycle when the fluorescence exceeds a threshold value. The data in the following table shows Ct values for three samples using real-time quantitative PCR.30 Each sample was analyzed 18 times.
| Sample X | Sample Y |
Sample Z |
|||
|
24.24 23.97 24.44 24.79 23.92 24.53 24.95 24.76 25.18 |
25.14 24.57 24.49 24.68 24.45 24.48 24.30 24.60 24.57 |
24.41 27.21 27.02 26.81 26.64 27.63 28.42 25.16 28.53 |
28.06 27.77 28.74 28.35 28.80 27.99 28.21 28.00 28.21 |
22.97 22.93 22.95 23.12 23.59 23.37 24.17 23.48 23.80 |
23.43 23.66 28.79 23.77 23.98 23.56 22.80 23.29 23.86 |
Examine this data statistically and write a brief report on your conclusions. Issues you may wish to address include the presence of outliers in the samples, a summary of the descriptive statistics for each sample, and any evidence for a difference between the samples.
4.9.3 Solutions to Practice Exercises
Practice Exercise 4.1
Mean: To find the mean we sum up the individual measurements and divide by the number of measurements. The sum of the 10 concentrations is 1405. Dividing the sum by 10 gives the mean as 140.5, or 1.40×102 mmol/L.
Median: To find the median we arrange the 10 measurements from the smallest concentration to the largest concentration; thus
118 132 137 140 141 143 143 145 149 157
The median for a data set with 10 members is the average of the fifth and sixth values; thus, the median is (141 + 143)/2, or 141 mmol/L.
Range: The range is the difference between the largest value and the smallest value; thus, the range is 157 – 118 = 39 mmol/L.
Standard Deviation: To calculate the standard deviation we first calculate the difference between each measurement and the mean value (140.5), square the resulting differences, and add them together. The differences are
-0.5 2.5 0.5 -3.5 -8.5 16.5 2.5 8.5 -22.5 4.5
and the squared differences are
0.25 6.25 0.25 12.25 72.25 272.25 6.25 72.25 506.25 20.25
The total sum of squares, which is the numerator of equation 4.1, is 968.50. The standard deviation is
\[s = \sqrt{\dfrac{968.50}{10 - 1}} = 10.37 ≈ 10.4\]
Variance: The variance is the square of the standard deviation, or 108.
Click here to return to the chapter.
Practice Exercise 4.2
The first step is to determine the concentration of Cu2+ in the final solution. The mass of copper is
\[\mathrm{74.2991\: g - 73.3216\: g = 0.9775\: g\: Cu}\]
The 10 mL of HNO3 used to dissolve the copper does not factor into our calculation. The concentration of Cu2+ is
\[\mathrm{\dfrac{0.9775\: g\: Cu}{0.5000\: L} × \dfrac{1.000\: mL}{250.0\: mL} × \dfrac{10^3\: mg}{g} = 7.820\: mg\: Cu^{2+} / L}\]
Having found the concentration of Cu2+ we continue on to complete the propagation of uncertainty. The absolute uncertainty in the mass of Cu wire is
\[u_\ce{g\:Cu} = \sqrt{(0.0001)^2 + (0.0001)^2} = \mathrm{0.00014\: g}\]
The relative uncertainty in the concentration of Cu2+ is
\[\mathrm{\dfrac{\mathit{u}_{mg /L}}{7.820\: mg/L}} = \sqrt{\left(\dfrac{0.00014}{0.9775}\right)^2 + \left(\dfrac{0.20}{500.0}\right)^2 + \left(\dfrac{0.006}{1.000}\right)^2 + \left(\dfrac{0.12}{250.0}\right)^2} = 0.00603\]
Solving for umg/L gives the uncertainty as 0.0472. The concentration and uncertainty for Cu2+ is 7.820 mg/L ± 0.047 mg/L.
Click here to return to the chapter.
Practice Exercise 4.3
The first step is to calculate the absorbance, which is
\[A = - \log \dfrac{P}{P_\ce{o}} = -\log \dfrac{1.50×10^2}{3.80×10} = \log(0.3947) = 0.4037 ≈ 0.404\]
Having found the absorbance we continue on to complete the propagation of uncertainty. First, we find the uncertainty for the ratio P/Po.
\[\dfrac{u_{P/P_\ce{o}}}{P/P_\ce{o}} = \sqrt{\left(\dfrac{15}{3.80×10^2}\right)^2 + \left(\dfrac{15} {1.50×10^2}\right)^2} = 1.075×10^{-2}\]
Finally, from Table 4.10 the uncertainty in the absorbance is
\[u_A = 0.4343 × \dfrac{u_{P/P_\ce{o}}}{P/P_\ce{o}} = (0.4343) × (1.075×10^{-2}) = 4.669×10^{-3}\]
The absorbance and uncertainty is 0.404 ± 0.005 absorbance units.
Click here to return to the chapter.
Practice Exercise 4.4
An uncertainty of 0.8% is a relative uncertainty in the concentration of 0.008; thus
\[0.008 = \sqrt{\left(\dfrac{0.028}{23.41}\right)^2 + \left(\dfrac{u_{k_\ce{A}}}{0.186}\right)^2}\]
Squaring both sides of the equation gives
\[6.4×10^{-5} = \left(\dfrac{0.028}{23.41}\right)^2 + \left(\dfrac{u_{k_\ce{A}}}{0.186}\right)^2\]
\[6.257×10^{-5} = \left(\dfrac{u_{k_\ce{A}}}{0.186}\right)^2\]
Sovling for ukA gives its value as 1.47×10–3, or ±0.0015 ppm–1.
Click here to return to the chapter.
Practice Exercise 4.5
To find the percentage of tablets containing less than 245 mg of aspirin we calculate the deviation, z,
\[z = \dfrac{245 − 250}{5} = -1.00\]
and look up the corresponding probability in Appendix 3A, obtaining a value of 15.87%. To find the percentage of tablets containing less than 240 mg of aspirin we find that
\[z = \dfrac{240 − 250}{5} = -2.00\]
which corresponds to 2.28%. The percentage of tablets containing between 240 and 245 mg of aspiring is 15.87% – 2.28% = 13.59%.
Click here to return to the chapter.
Practice Exercise 4.6
The mean is 249.9 mg aspirin/tablet for this sample of seven tablets. For a 95% confidence interval the value of z is 1.96. The confidence interval is
\[\mathrm{249.9 ± \dfrac{1.96×5}{\sqrt{7}} = 249.9 ± 3.7 ≈ 250\: mg ± 4\:mg}\]
Click here to return to the chapter.
Practice Exercise 4.7
With 100 pennies, we have 99 degrees of freedom for the mean. Although Table 4.15 does not include a value for t(0.05, 99), we can approximate its value using the values for t(0.05, 60) and t(0.05, 100) and assuming a linear change in its value.
\[t(0.05, 99) = t(0.05, 60) - \dfrac{39}{40}\left\{t(0.05, 60) - t(0.05, 100)\right\}\]
\[t(0.05, 99) = 200 - \dfrac{39}{40}\left\{2.000 -1.984\right\} = 1.984\]
The 95% confidence interval for the pennies is
\[\mathrm{3.095 ± \dfrac{1.9844×0.0346}{\sqrt{100}} = 3.095\: g ± 0.007\:g}\]
From Example 4.15, the 95% confidence intervals for the two samples in Table 4.11 are 3.117 g ± 0.047 g and 3.081 g ± 0.046 g. As expected, the confidence interval for the sample of 100 pennies is much smaller than that for the two smaller samples of pennies. Note, as well, that the confidence interval for the larger sample fits within the confidence intervals for the two smaller samples.
Click here to return to the chapter.
Practice Exercise 4.8
The null hypothesis is H0 : X = μ and the alternative hypothesis is HA : X ≠ μ. The mean and standard deviation for the data are 99.26% and 2.35%, respectively. The value for texp is
\[t_\ce{exp} = \dfrac{|100.0 - 99.26|\sqrt{7}}{2.35} = 0.833\]
and the critical value for t(0.05, 6) is 0.836. Because texp is less than t(0.05, 6) we retain the null hypothesis and have no evidence for a significant difference between X and μ.
Click here to return to the chapter.
Practice Exercise 4.9
The standard deviations for Lot 1 is 6.451 mg, and 7.849 mg for Lot 2. The null and alternative hypotheses are
\[H_0 : s_\textrm{Lot 1}^2 = s_\textrm{Lot 2}^2 \hspace{20px} H_\ce{A} : s_\textrm{Lot 1}^2 ≠ s_\textrm{Lot 2}^2\]
and the value of Fexp is
\[F_\ce{exp} = \dfrac{(7.849)^2}{(6.451)^2} = 1.480\]
The critical value for F(0.05, 5, 6) is 5.988. Because Fexp < F(0.05, 5, 6), we retain the null hypothesis. There is no evidence at α = 0.05 to suggest that the difference in the variances is significant.
Click here to return to the chapter.
Practice Exercise 4.10
To compare the means for the two lots, we will use an unpaired t-test of the null hypothesis H0 : XLot 1 = XLot 2 and the alternative hypothesis HA : XLot 1 ≠ XLot 2. Because there is no evidence suggesting a difference in the variances (see Practice Exercise 4.9) we pool the standard deviations, obtaining an spool of
\[s_\ce{pool} = \sqrt{\dfrac{(7−1)(6.451)^2 + (6-1)(7.849)^2}{7+6-2}} = 7.121\]
The means for the two samples are 249.57 mg for Lot 1 and 249.00 mg for Lot 2. The value for texp is
\[t_\ce{exp} = \dfrac{|249.57 - 249.00|}{7.121} × \sqrt{\dfrac{7×6}{7+6}} = 0.1439\]
The critical value for t(0.05, 11) is 2.204. Because texp is less than t(0.05, 11), we retain the null hypothesis and find no evidence at α = 0.05 for a significant difference between the means for the two lots of aspirin tablets.
Click here to return to the chapter.
Practice Exercise 4.11
Treating as Unpaired Data: The mean and standard deviation for the concentration of Zn2+ at the air-water interface are 0.5178 mg/L and 0.1732 mg/L respectively, and the values for the sediment-water interface are 0.4445 mg/L and 0.1418 mg/L. An F-test of the variances gives an Fexp of 1.493 and an F(0.05, 5, 5) of 7.146. Because Fexp is smaller than F(0.05, 5,5) we have no evidence at α = 0.05 to suggest that the difference in variances is significant. Pooling the standard deviations gives an spool of 0.1582 mg/L. An unpaired t-test gives texp as 0.8025. Because texp is smaller than t(0.05, 11), which is 2.204, we have no evidence that there is a difference in the concentration of Zn2+ between the two interfaces.
Treating as Paired Data: To treat as paired data we need to calculate the difference, di, between the concentration of Zn2+ at the air-water interface and at the sediment-water interface for each location.
\[d_i =([\ce{Zn^{2+}}]_\textrm{air-water})_i - ([\ce{Zn^{2+}}]_\textrm{sed-water})_i\]
|
Location di (mg/L) |
1 0.015 |
2 0.028 |
3 0.067 |
4 0.121 |
5 0.102 |
6 0.107 |
The mean difference is 0.07333 mg/L with a standard deviation of 0.0441 mg/L. The null hypothesis and alternative hypothesis are
\[H_0 : \overline{d} = 0 \hspace{20px} H_\ce{A} : \overline{d} ≠ 0\]
and the value of texp is
\[t_\ce{exp} = \dfrac{|0.07333| \sqrt{6}}{0.04410} = 4.073\]
Because texp is greater than t(0.05, 5), which is 2.571, we reject the null hypothesis and accept the alternative hypothesis that there is a significant difference in the concentration of Zn2+ between the air-water interface and the sediment-water interface.
The difference in the concentration of Zn2+ between locations is much larger than the difference in the concentration of Zn2+ between the interfaces. Because out interest is in studying differences between the interfaces, the larger standard deviation when treating the data as unpaired increases the probability of incorrectly retaining the null hypothesis, a type 2 error.
Click here to return to the chapter.
Practice Exercise 4.12
You will find small differences between the values given here for texp and Fexp, and for those values shown with the worked solutions in the chapter. These differences arise because Excel does not round off the results of intermediate calculations.
The two snapshots of Excel spreadsheets shown in Figure 4.29 provide solutions to these two examples.
Click here to return to the chapter.
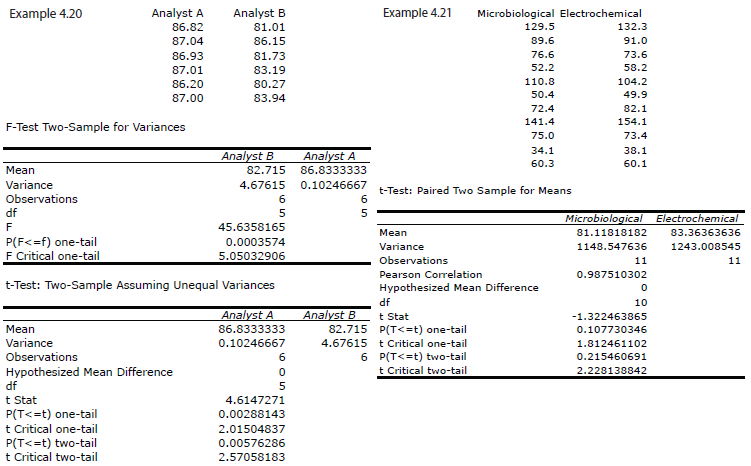
Figure 4.29 Excel’s output for the data in Practice Exercise 4.12.
Practice Exercise 4.13
Shown here are copies of R sessions for each problem. You will find small differences between the values given here for texp and Fexp, and for those values shown with the worked solutions in the chapter. These differences arise because R does not round off the results of intermediate calculations.
Example 4.20
> AnalystA=c(86.82, 87.04, 86.93, 87.01, 86.20, 87.00)
> AnalystB=c(81.01, 86.15, 81.73, 83.19, 80.27, 83.94)
> var.test(AnalystB, AnalystA)
F test to compare two variances
data: AnalystB and AnalystA
F = 45.6358, num df = 5, denom df = 5, p-value = 0.0007148
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
6.385863 326.130970
sample estimates:
ratio of variances
45.63582
> t.test(AnalystA, AnalystB, var.equal=FALSE)
Welch Two Sample t-test
data: AnalystA and AnalystB
t = 4.6147, df = 5.219, p-value = 0.005177
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
1.852919 6.383748
sample estimates:
mean of x mean of y
86.83333 82.71500
Example 4.21
> micro=c(129.5, 89.6, 76.6, 52.2, 110.8, 50.4, 72.4, 141.4, 75.0, 34.1, 60.3)
> elect=c(132.3, 91.0, 73.6, 58.2, 104.2, 49.9, 82.1, 154.1, 73.4, 38.1, 60.1)
> t.test(micro,elect,paired=TRUE)
Paired t-test
data: micro and elect
t = -1.3225, df = 10, p-value = 0.2155
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-6.028684 1.537775
sample estimates:
mean of the differences
-2.245455
Click here to return to the chapter.
Practice Exercise 4.14
Because we are selecting a random sample of 100 members from a uniform distribution, you will see subtle differences between your plots and the plots shown as part of this answer. Here is a record of my R session and the resulting plots.
> data=runif(100, min=0, max=0)
> data
[1] 18.928795 80.423589 39.399693 23.757624 30.088554
[6] 76.622174 36.487084 62.186771 81.115515 15.726404
[11] 85.765317 53.994179 7.919424 10.125832 93.153308
[16] 38.079322 70.268597 49.879331 73.115203 99.329723
[21] 48.203305 33.093579 73.410984 75.128703 98.682127
[26] 11.433861 53.337359 81.705906 95.444703 96.843476
[31] 68.251721 40.567993 32.761695 74.635385 70.914957
[36] 96.054750 28.448719 88.580214 95.059215 20.316015
[41] 9.828515 44.172774 99.648405 85.593858 82.745774
[46] 54.963426 65.563743 87.820985 17.791443 26.417481
[51] 72.832037 5.518637 58.231329 10.213343 40.581266
[56] 6.584000 81.261052 48.534478 51.830513 17.214508
[61] 31.232099 60.545307 19.197450 60.485374 50.414960
[66] 88.908862 68.939084 92.515781 72.414388 83.195206
[71] 74.783176 10.643619 41.775788 20.464247 14.547841
[76] 89.887518 56.217573 77.606742 26.956787 29.641171
[81] 97.624246 46.406271 15.906540 23.007485 17.715668
[86] 84.652814 29.379712 4.093279 46.213753 57.963604
[91] 91.160366 34.278918 88.352789 93.004412 31.055807
[96] 47.822329 24.052306 95.498610 21.089686 2.629948
> histogram(data, type=”percent”)
> densityplot(data)
> dotchart(data)
> bwplot(data)
Figure 4.30 shows the four plots. The histogram divides the data into eight bins, each containing between 10 and 15 members. As we expect for a uniform distribution, the histogram’s overall pattern suggests that each outcome is equally probable. In interpreting the kernel density plot it is important to remember that it treats each data point as if it is from a normally distributed population (even though, in this case, the underlying population is uniform). Although the plot appears to suggest that there are two normally distributed populations, the individual results shown at the bottom of the plot provide further evidence for a uniform distribution. The dot chart shows no trend along the y-axis, indicating that the individual members of this sample were drawn randomly from the population. The distribution along the x-axis also shows no pattern, as expected for a uniform distribution, Finally, the box plot shows no evidence of outliers.
Click here to return to the chapter.

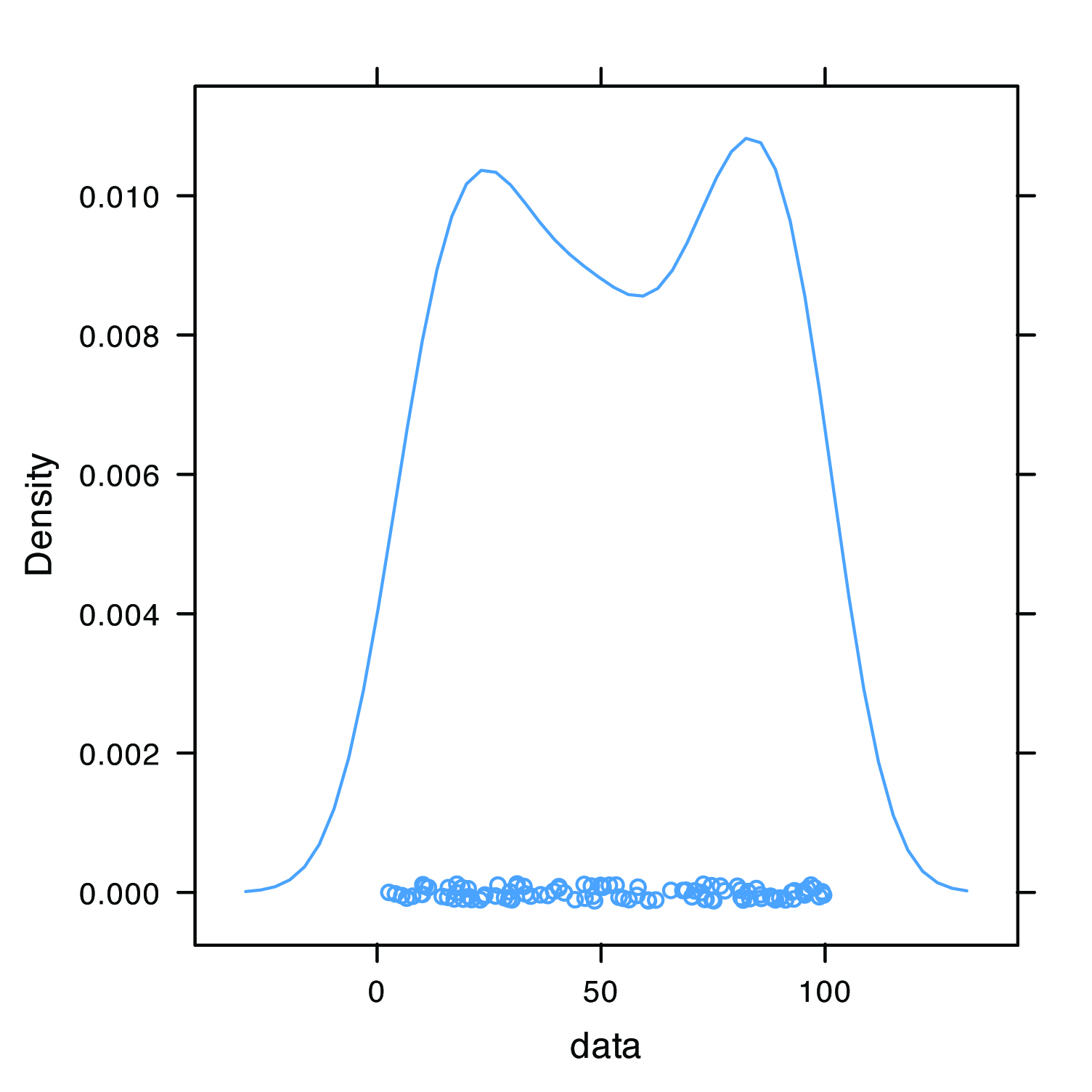
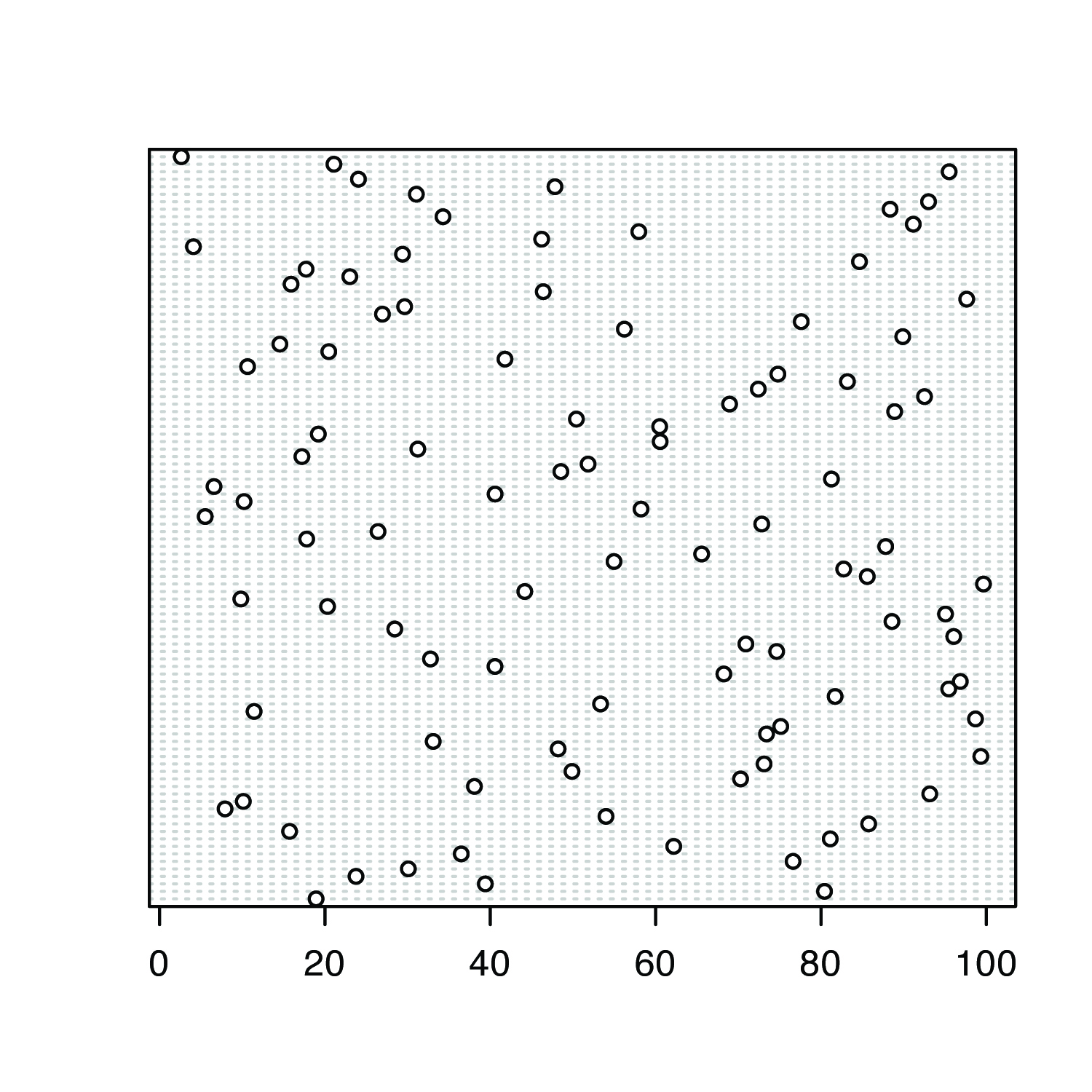

Figure 4.30 Plots generated using R to solve Practice Exercise 4.13.