
2.2: Connection Tables
- Page ID
- 154257
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)- Introduce concept of Connection Table
- Introduce shortcomings of Simplified Connection Table
Introduction
A connection table is a data table that provides information a computer needs to generate a molecular graph. Specifically, it needs to define what the atoms are, and how they are connected, that is, the edges and the nodes of the graph. This is typically done in a file, and in the file are a minimum of two tables, the atom table and the bond table. But the file can also have additional information, like what isotopes are present, or what are the 3-D coordinates for a particular conformation.
Thus, this section will be broken up into several parts. First, we will discuss a Simplified Connection Table (SCT) to get a feel for the basic logic behind a connection table. Then we will look at some real files that students will be required to download from databases and work with.
Simplified Connection Table (SCT)
The purpose of this section is to give the student a feel for the issues associated with creating a connection table that can generate a molecular graph. The SCT is not a real file, but a description of the data within a file that the computer needs to be able to "read". Real files using connection tables will be approached in section 2.5 Structural Data Files. In essence, there are two tables, the atom table and the bond table.
- The atom table provides an index number for each atom. It may provide index numbers for the hydrogen (explicit representations), or it may not (implicit representations).
- The bond table uses the index number of the atom table to define what atoms are bonded to each other, and the types of bonds. The bond order is defined by a number, where 1 is a single bond, 2 is a double bond and 3 is a triple bond.
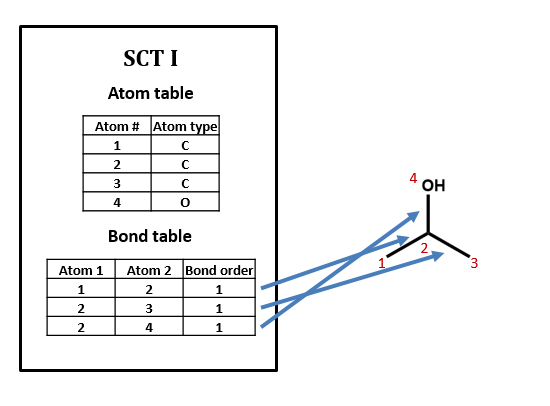
Figure \(\PageIndex{1}\): SCT for isopropanol.
Are connection tables unique?
No, there can be many ways of assigning index numbers to the atoms in a connection table, and one would need to use an algorithm for generating a canonical connection table. For n atoms there are n! (n factorial) ways of assigning index numbers. From figure 2.2.2, if any of the four atoms is assigned the value of 1, there are 6 ways you can assign the remaining three atoms, and since there are 4 atoms you can assign the value of 1 to, there are 24 ways to assign the above index numbers, which is 4!.
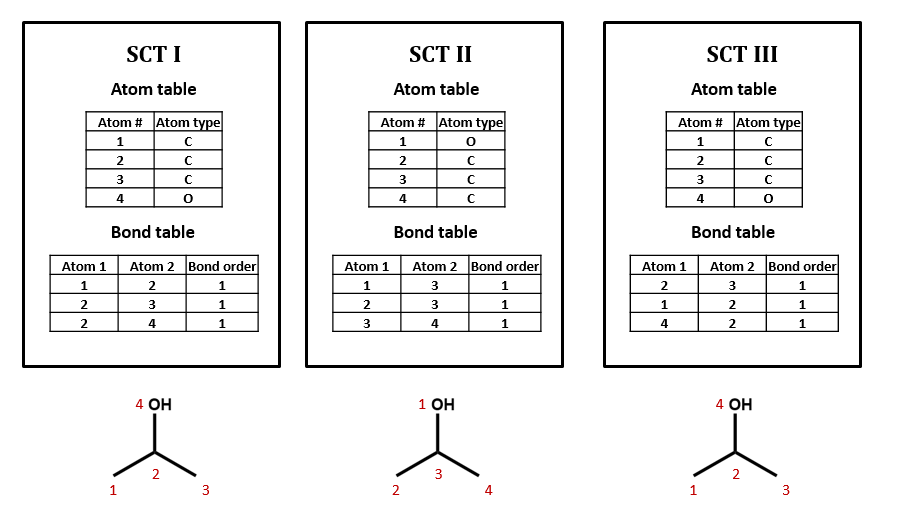
Figure \(\PageIndex{2}\): Three possible ways of assigning index numbers to a connection table for isopropanol.
Was the above connection table explicit or implicit in the assignment of hydrogens?
The above connection table is implicit in the assignment of hydrogens, and algorithms based on a set of valency rules could determine the number of hydrogens. Figure 2.2.3 has explicit hydrogens for isopropanol.
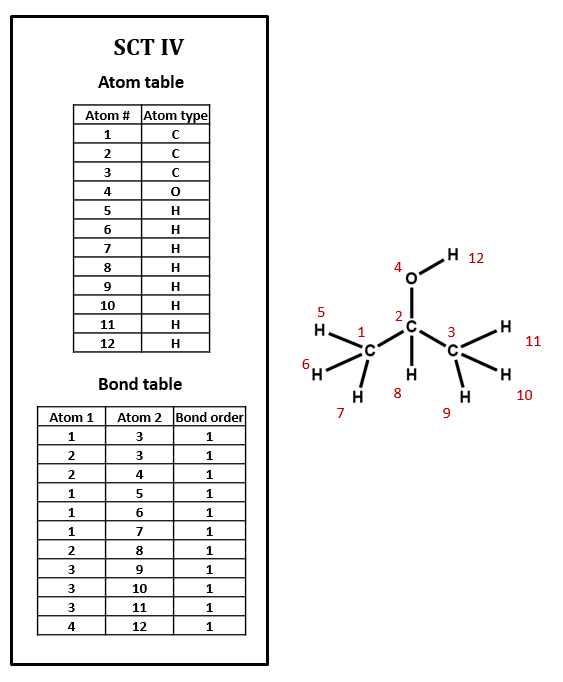
Figure \(\PageIndex{3}\): Isopropanol connection table with explicit hydrogens.
By comparing figures 2.2.2 and 2.2.3 you can see how the implicit table is simpler and would result in a smaller file.
Can you see what is wrong with the Bond table in figure \(\PageIndex{3}\)?
- Answer
-
Note that atom 2 is only in three bonds, and atom three is in five bonds, and that somehow, atom 3 is attached to atom 1.
SCT Shortcomings
The Simplified Connection Table is at the core of graph theory representation of chemical entities in that it provides the critical information of what atoms are present and where the bonds are. In section 2.5 we will look at several structural data files that are built around connection tables, but before that it is prudent to identify many of the issues with molecular representation that a crude SCT does not cover, and these will be outlined in section 2.3. There are sort of three basic types of shortcomings to connection tables.
The first is that real molecules are dynamic 3 dimensional structures and so a real data file needs to define the relative coordinates of the atoms, which is typically done by adding a 3D coordinate layer to the atom table (section 2.5). The fact that molecules are dynamic means the bonds are both vibrating and rotating, with the later resulting in multiple conformations (different orientations) of the atoms over time. Atomic coordinates typically represent the most stable orientation as determined through computational calculations that minimize the energy of the system and take into account environmental factors. This means the coordinates of a molecule in free space may be completely different than in a protein environment, and so it is important that you understand how the coordinates in a molecular data file were generated, and if they are appropriate to your needs.
The second shortcoming to connection tables is actually structural in nature, and often a SCT does not provide enough information to uniquely describe a molecular species. In the case of isopropanol above, there were 24 connection tables that described the molecule, but they all described the same molecule, that is, they described isoproponal. Sterioisomerism is a case where two different molecules (say cis and trans dichlorethene) would have the same connection table, and so stereo isomers would require additional information to uniquely distinguish between the two isomers. Other areas where issues with SCT arise include resonance structures, aromaticity, tautomers, multcovalent units, coordination complexes, conjugate acid/base equilibrium and the like. To handle these issues additional data beyond that of the SCT. These will be discussed in section 2.3 Molecular Graph Issues.
The third potential issue with connection table based representation of chemicals is more functional in nature, in that they are bulky files and hard to read by a human. Line notation is a string of characters, like a word, which describes the molecule. One could consider line notation to be nomenclature for computers in the sense that a string of characters represents a :word". In reality, line notations are often converted to connection tables when software agents are doing calculations because many of the software algorithms are based on manipulating connection tables.
The shortcomings of connection tables will be picked up again when we look at real structural data files and how they handle these situations.
Contributors
Robert E. Belford (University of Arkansas Little Rock; Department of Chemistry). The breadth, depth and veracity of this work is the responsibility of Robert E. Belford, rebelford@ualr.edu. You should contact him if you have any concerns. This material has both original contributions, and content built upon prior contributions of the LibreTexts Community and other resources, including but not limited to:
- Evan Hepler-Smith
- Leah McEwen
(Material adopted from the Spring 2017 Cheminformatics OLCC)