
2.3: DNA and RNA Metabolism
- Page ID
- 308329

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)After completing this lesson, you will be able to:
- Understand the mechanism of DNA replication.
- Understand the process of gene expression.
- List the main types of DNA mutation and mechanism of DNA repair.
DNA Replication
The process of DNA replication consists of uncoiling double-stranded DNA, copying each DNA strand and then separating the two, new, double-stranded copies. The process starts at an origin of replication (ori), a nucleic acids sequence where the replication can start. There are around 100,000 origins of replication in each human cell. This means that the DNA replication may start simultaneously in different positions at the same time. The replication fork is the point where two DNA strands, one termed the leading strand and the other the lagging strand, are separated and DNA copying occurs. The coiled-coil, double-helical DNA structure is initially unwound by the enzyme DNA helicase by breaking the hydrogen bonds between complementary nucleic acids. Single-stranded binding proteins attach to the new DNA strands to keep them separated.
An enzyme termed primase then produces a short strand of RNA to serve as a primer for the remainder of the process. The enzyme DNA polymerase replicates each DNA strand in the 5′ to 3′ direction by adding the correct, matching nucleotide triphosphate to the 3′-hydroxyl end of the primer strand. As each new nucleic acid is added, a new phosphodiester bond is formed, utilizing the energy contained in the remaining diphosphate group.

RNA Transcription
RNA Transcription is the process whereby a particular segment of DNA is transcripted into an equivalent RNA sequence.
- mRNA: For genes that codes for a protein.
- tRNA: For a transfer RNA.
- rRNA: For assembly of a ribosome.
- miRNA (micro RNA): Which binds to mRNA and inhibits its translation.
- siRNA (small-interfering RNA): Which binds to mRNA and aids in its degradation.
- snRNA (small nuclear RNA): Which participates in RNA processing as part of the spliceosomes.
- snoRNA (small nucleolar RNA): Which participate in nucleolar RNA processing.
The transcription starts with binding of the enzyme RNA polymerase to a promoter sequence on the DNA, a regulatory region that dictates where the transcription should start.
The DNA is transcribed from 3′ to 5′ and occurs only on one of the DNA strands, the template strand.
As in DNA replication, energy for the formation of the phosphodiester bond is derived from hydrolysis of the two terminal phosphate bonds of the nucleoside triphosphate.
Multiple RNA polymerases can transcribe on a single DNA gene sequence, allowing rapid production of the RNA product.

Enhancer: This is a short region of DNA that can be bound by transcription factors to increase or facilitate the transcription of a particular gene. They can be located up away from the gene, upstream, or downstream from the start site.
Transcription Factors (TFs): These include a wide number of proteins, excluding RNA polymerase, that promotes (as an activator), or blocks (as a repressor) the recruitment of RNA polymerase to DNA. TFs bind to promoter regions of DNA.
Promoter Region: These are specific DNA sequences, usually located upstream and near the transcription start sites of genes and serves as a binding site for proteins called transcription factors that recruit RNA polemerase. Example: TATA bos, CpG island.
Figure \(\PageIndex{1}\): Machinery of RNA transcription
RNA Processing
The newly synthesized RNA transcripts are processed prior to their use in the cell as mature RNA.

A 7-methyl guanosine nucleic acid is added to the 5′-end (known as a 5′ cap) of the pre-mRNA as it emerges from RNA polymerase II (Pol II). The cap protects the RNA from being degraded by enzymes and serves as an assembly point for the proteins to begin translation to protein.
Removal of introns present in the pre-mRNA and splicing of the remaining exons, in a process called RNA splicing. The continuous series of DNA bases coding for a protein are interrupted by base sequences that are not translated. The translated sequences are referred to as exons (expressed sequences) and the nontranslated sequences as introns (intervening sequences). This completes the mRNA molecule, which is now ready for export to the cytosol. (The remainder of the transcript is degraded, and the RNA polymerase leaves the DNA.)
3.4 Protein Translation
Protein synthesis requires the interaction of mRNA, tRNA, several accessory proteins, called initiation factor (IF) and elongation (EF) factor, and ribosomes.
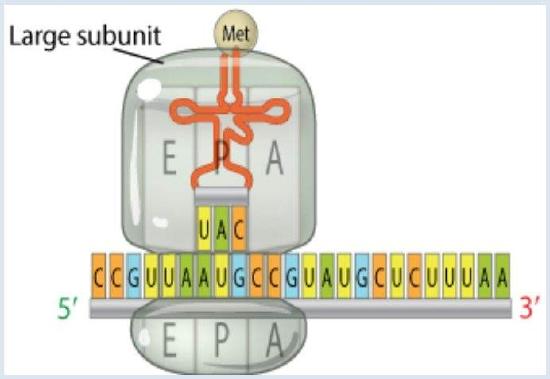 The large ribosomal subunit binds to the small ribosomal subunit to complete the initiation complex. The tRNA molecule bind to one amino acids at the top of the structure. In the base if the tRNA there is the three base sequence known as the anticodon. This anticodon binds, through base pairing, to a three base codon on mRNA. It is this interaction between the mRNA and the amino acid-tRNA that provides the high degree of fidelity observed in the transfer of genetic information from DNA to proteins.
The large ribosomal subunit binds to the small ribosomal subunit to complete the initiation complex. The tRNA molecule bind to one amino acids at the top of the structure. In the base if the tRNA there is the three base sequence known as the anticodon. This anticodon binds, through base pairing, to a three base codon on mRNA. It is this interaction between the mRNA and the amino acid-tRNA that provides the high degree of fidelity observed in the transfer of genetic information from DNA to proteins. The Triplet Code (Genetic Code)
The Triplet Code (Genetic Code)
A sequence of three bases in DNA identifies each of the 20 amino acids that are to be incorporated into the newly synthesized protein. This information is incorporated into mRNA which is synthesized using DNA as the template. Considering that three bases are required at a minimum, and we have 4 nucleotides ( 43 = 64 code words are possible). This is more than the 20 amino acids. In fact, many triplets are used to define one same amino acid. In addition, some “extra” triplet sequences are used as stop codons to terminate protein synthesis. AUG is used as the start codon for the N-terminal amino acid in eukaryotes.
Using the same binding rules as DNA double strands (e.g., a tRNA that binds the starting mRNA codon AUG has an anticodon sequence of UAC), insuring the specific order of AAs required for proper production of the protein.
Figure \(\PageIndex{4}\): Genetic code - © 2014 Nature Education
RNA plays three distinct and important roles:
- mRNA: The intermediary between gene and protein – provides the message.
- tRNA: The key or adaptor – reads the genetic code, brings amino acids to the growing polypeptide chain
- rRNA: In ribosome, provides a scaffold for protein synthesis, catalyzes peptide bond formation
The IF and EF accessory proteins serve a number of roles, including enabling binding of the mRNA molecule to the ribosome, movement of the mRNA along the ribosome to the start point of the synthesis, docking of the tRNA–amino acid, and movement of the mRNA and growing peptide chain, as well as accuracy assurance.
The protein biosynthesis, can be divided into three phases: initiation, elongation, and termination.
Initiation
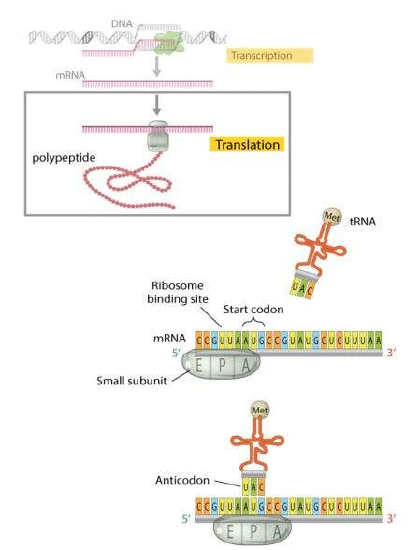
Initiation of protein synthesis begins when the protein initiator factor IF-3 binds to the small subunit of the ribosome and causes its dissociation. The small ribosomal subunit then binds to the 5’ side of mRNA which carries information in a triplet code from DNA. The small subunit is then translocated where it meets the large ribosomal subunit, other protein initiator factors, and initiator tRNA. The tRNA is bound to methionine at a site in the ribosome known as the P site.
Elongation
In the elongation phase of protein synthesis, a specific aminoacyl-tRNA, directed by hydrogen bonding interactions between the anticodon region of the aminoacyl-tRNA and the codon region of mRNA, adds to a site distinct from the P site, the A site. The A and P sites are in close proximity, allowing the peptide bond formation between the amino acids. The newly synthesized tRNA bound dipeptide then moves from the A site to the P site. After a translocation of the ribosome in the 5’ - 3’ direction along the mRNA occurs to expose a new codon. Then, another amino acid-tRNA identity and binds to the mRNA at the A site and the peptidyl transferase reaction is again initiated. As the polypeptide chain grows through subsequent cycles of amino acid residue incorporation, it emerges from the ribosome and undergoes folding into its native secondary and tertiary conformations.
Termination
In termination step, the peptide bond synthesis ceases when a stop codon on the mRNA is reached. This termination site will not bind aminoacyl-tRNA and peptide synthesis stops. Release factors allow the newly synthesized protein to dissociate from the ribosome.
3.5 Gene Expression
Gene expression is a two-step process in which DNA is converted into a protein.
 Step 1: The first step is DNA transcription to RNA. In this step, the information from the archival copy of DNA is imprinted into mRNA. The structure of RNA is a little different, it contains ribose instead of deoxyribose, and the four bases that bind to it are cytosine (C), guanine (G), adenine (A), and uracil (U). During transcription, DNA unfolds, and mRNA is created by pairing mRNA bases with the bases of DNA. In this process C in DNA translates to G, G to C, A to U, and T to A. After mRNA is transcripted it is transported to the ribosome.
Step 1: The first step is DNA transcription to RNA. In this step, the information from the archival copy of DNA is imprinted into mRNA. The structure of RNA is a little different, it contains ribose instead of deoxyribose, and the four bases that bind to it are cytosine (C), guanine (G), adenine (A), and uracil (U). During transcription, DNA unfolds, and mRNA is created by pairing mRNA bases with the bases of DNA. In this process C in DNA translates to G, G to C, A to U, and T to A. After mRNA is transcripted it is transported to the ribosome.
Step 2: The second step, protein translation occurs at the ribosome. During translation, the sequence of codons (triplet of bases) of mRNA is, with the help of tRNA, translated into a sequence of amino acids
Figure \(\PageIndex{5}\): Gene expression seems to be a straightforward process, the mechanism that control the gene expression that causes most phenotypic differences in organisms.
3.6 Mutation
 Mutations are changes in the genetic sequence (DNA or RNA sequence) , and they are a main cause of diversity among organisms. Although some of mutations are beneficial, offering resistance to disease or improved structure and/or function, some other specific mutations can lead to disease and/or death of the cell or organism.
Mutations are changes in the genetic sequence (DNA or RNA sequence) , and they are a main cause of diversity among organisms. Although some of mutations are beneficial, offering resistance to disease or improved structure and/or function, some other specific mutations can lead to disease and/or death of the cell or organism.
Mutations can occur due to assaults from the environment or spontaneous mutation may occur during the DNA replication. Mutations are estimated to occur at an approximate rate of 1000–1,000,000 per cell per day in the human genome, and every new cell is believed to contain approximately 120 new mutations.
TYPES OF MUTATION
Point mutations when only a single base pair is changed into another base pair. They can be classified as the following:
- Transition: When a purine nucleotide is changed to a different purine (A ↔ G) or a pyrimidine nucleotide is changed to a different pyrimidine nucleotide [C ↔ T(U)].
- Transversion: When the orientation of a single purine and pyrimidine nucleotide is reversed [A/G ↔ C/T(U)].
- Silent: When the same AA is coded.
- Missense: When a different AA is coded.
- Neutral: When an AA change occurs but does not affect the protein's structure or function.
- Nonsense: When a stop codon results, terminating translation and shortening the resulting protein.
Insertion and deletion mutations, which are together known as indels. Indels can have a wide variety of lengths. At the short end of the spectrum, indels of one or two base pairs within coding sequences have the greatest effect, because they will inevitably cause a frameshift, i.e. change the entire reading of the mRNA sequence. At the intermediate level, indels can affect parts of a gene or whole groups of genes. At the largest level, whole chromosomes or even whole copies of the genome can be affected by insertions or deletions. At this high level, it is also possible to invert or translocate entire sections of a chromosome, and chromosomes can even fuse or break apart.
If a large number of genes are lost as a result of one of these processes, then the consequences are usually very harmful.
3.7 DNA Repair
The human body have mechanisms to detect and repair the various types of damage that can occur to DNA, no matter whether this damage is caused by the environment or by errors in replication.
Because DNA is a molecule that plays an active and critical role in cell division, during the cell cycle, checkpoint mechanisms ensure that the DNA is intact before permitting DNA replication and cell division to occur. Failures in these checkpoints can lead to an accumulation of damage, which in turn leads to mutations.
UV radiation causes DNA lesions that may distort DNA's structure, introducing bends or kinks and thereby impeding transcription and replication. These lesions may be repaired through a process known as nucleotide excision repair (NER), a mechanism where an enzyme catalyze the removal of damaged nucleotides, and replacement of the correct sequence, guided by the intact complementary DNA strand. Defects in this mechanism is related to human diseases like skin cancer.
Another repair mechanism that handles the spontaneous DNA damage caused oxidation or hydroxylation generated by metabolism is the base excision repair (BER). In this mechanism, enzymes known as DNA glycosylases remove damaged bases by literally cutting them out of the DNA strand through cleavage of the covalent bonds between the bases and the sugar-phosphate backbone. The resulting gap is then filled by a specialized repair polymerase and sealed by ligase.
DNA damage also may occur in form of double-strand breaks, which are caused by ionizing radiation, including gamma rays and X-rays. Double-strand breaks may be repaired through one of two mechanisms: nonhomologous end joining (NHEJ), where an enzyme called DNA ligase IV uses overhanging pieces of DNA adjacent to the break to join and fill in the ends; or homologous recombination repair (HRR) where the homologous chromosome itself is used as a template for repair.

Topic 3: Key Points
In this section, we explored the following main points:
- The process of DNA replication is controlled by several proteins that act together to assure the correct base pairing for creation of the new DNA strand.
- Transcription is the first step of gene expression, in which a particular segment of DNA is copied into RNA (mRNA) by the enzyme RNA polymerase.
- In translation, messenger RNA (mRNA)—produced by transcription from DNA—is decoded by a ribosome and tRNA to produce a specific amino acid chain, or protein.
- Mutations are changes in the genetic sequence (DNA or RNA sequence), that can be beneficial or may result in damage, if not repaired.
1. RNA splicing is the process which involves the removal of introns present in the pre-mRNA and splicing of the remaining exons. True or False?
True
False
- Answer
-
true
2. Which of the following does not belong to the process of DNA replication?
Primase
DNA Polymerase
RNA Polymerase
- Answer
-
RNA Polymerase
3. During protein translation, the sequence of codons (triplets of bases) of mRNA is important to:
Maintain the structure of the mRNA
Translated the correct a sequence of amino acids.
DNA replication
- Answer
-
Translated the correct a sequence of amino acids.