
23.7: DNA Replication, the Double Helix, and Protein Synthesis
- Page ID
- 219342
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Skills to Develop
- Identify the two types of nucleic acids and the function of each type.
- Describe how nucleotides are linked together to form nucleic acids.
- Describe the secondary structure of DNA and the importance of complementary base pairing.
Nucleic acids are large polymers formed by linking nucleotides together and are found in every cell. Deoxyribonucleic acid (DNA) is the nucleic acid that stores genetic information. If all the DNA in a typical mammalian cell were stretched out end to end, it would extend more than 2 m. Ribonucleic acid (RNA) is the nucleic acid responsible for using the genetic information encoded in DNA to produce the thousands of proteins found in living organisms.
Primary Structure of Nucleic Acids
Nucleotides are joined together through the phosphate group of one nucleotide connecting in an ester linkage to the OH group on the third carbon atom of the sugar unit of a second nucleotide. This unit joins to a third nucleotide, and the process is repeated to produce a long nucleic acid chain (Figure \(\PageIndex{1}\)). The backbone of the chain consists of alternating phosphate and sugar units (2-deoxyribose in DNA and ribose in RNA). The purine and pyrimidine bases branch off this backbone.
Each phosphate group has one acidic hydrogen atom that is ionized at physiological pH. This is why these compounds are known as nucleic acids.
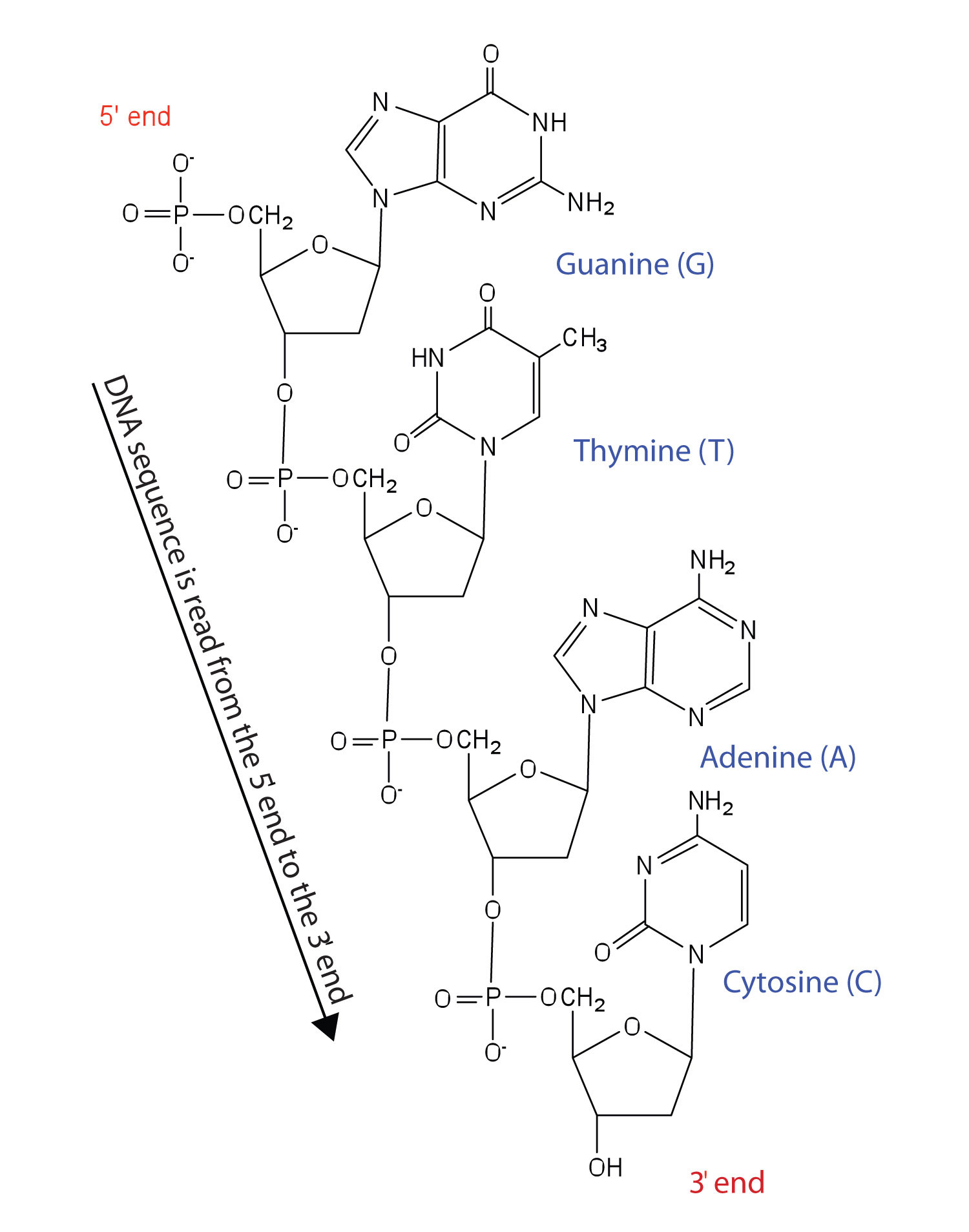
Figure \(\PageIndex{1}\) Structure of a Segment of DNA. A similar segment of RNA would have OH groups on each C2′, and uracil would replace thymine.
Like proteins, nucleic acids have a primary structure that is defined as the sequence of their nucleotides. Unlike proteins, which have 20 different kinds of amino acids, there are only 4 different kinds of nucleotides in nucleic acids. For amino acid sequences in proteins, the convention is to write the amino acids in order starting with the N-terminal amino acid. In writing nucleotide sequences for nucleic acids, the convention is to write the nucleotides (usually using the one-letter abbreviations for the bases, shown in Figure \(\PageIndex{1}\)) starting with the nucleotide having a free phosphate group, which is known as the 5′ end, and indicate the nucleotides in order. For DNA, a lowercase d is often written in front of the sequence to indicate that the monomers are deoxyribonucleotides. The final nucleotide has a free OH group on the 3′ carbon atom and is called the 3′ end. The sequence of nucleotides in the DNA segment shown in Figure \(\PageIndex{1}\) would be written 5′-dG-dT-dA-dC-3′, which is often further abbreviated to dGTAC or just GTAC.
Secondary Structure of DNA
The three-dimensional structure of DNA was the subject of an intensive research effort in the late 1940s to early 1950s. Initial work revealed that the polymer had a regular repeating structure. In 1950, Erwin Chargaff of Columbia University showed that the molar amount of adenine (A) in DNA was always equal to that of thymine (T). Similarly, he showed that the molar amount of guanine (G) was the same as that of cytosine (C). Chargaff drew no conclusions from his work, but others soon did.
At Cambridge University in 1953, James D. Watson and Francis Crick announced that they had a model for the secondary structure of DNA. Using the information from Chargaff’s experiments (as well as other experiments) and data from the X ray studies of Rosalind Franklin (which involved sophisticated chemistry, physics, and mathematics), Watson and Crick worked with models that were not unlike a child’s construction set and finally concluded that DNA is composed of two nucleic acid chains running antiparallel to one another—that is, side-by-side with the 5′ end of one chain next to the 3′ end of the other. Moreover, as their model showed, the two chains are twisted to form a double helix—a structure that can be compared to a spiral staircase, with the phosphate and sugar groups (the backbone of the nucleic acid polymer) representing the outside edges of the staircase. The purine and pyrimidine bases face the inside of the helix, with guanine always opposite cytosine and adenine always opposite thymine. These specific base pairs, referred to as complementary bases, are the steps, or treads, in our staircase analogy (Figure \(\PageIndex{2}\)).
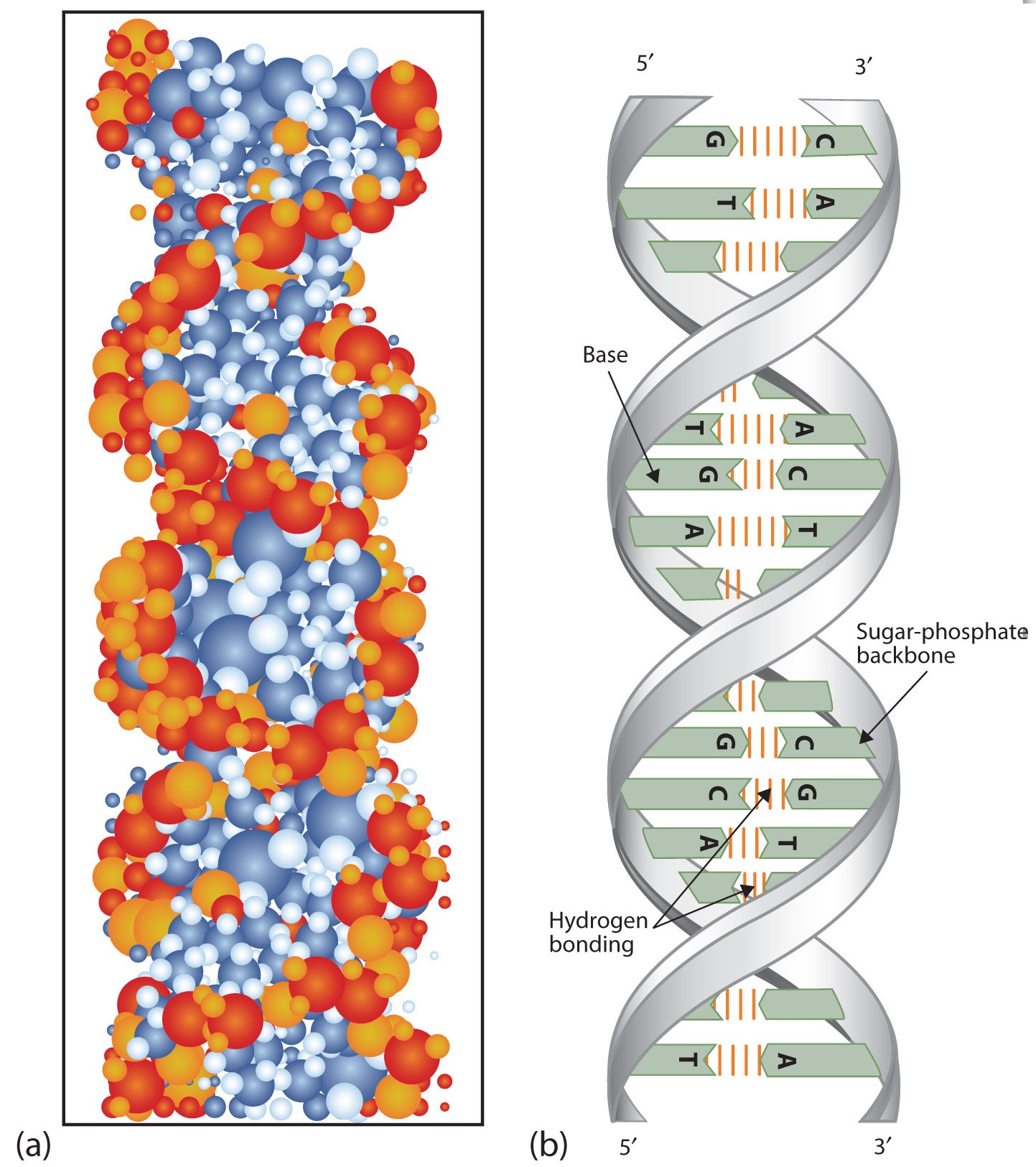
Figure \(\PageIndex{2}\) DNA Double Helix. (a) This represents a computer-generated model of the DNA double helix. (b) This represents a schematic representation of the double helix, showing the complementary bases.
The structure proposed by Watson and Crick provided clues to the mechanisms by which cells are able to divide into two identical, functioning daughter cells; how genetic data are passed to new generations; and even how proteins are built to required specifications. All these abilities depend on the pairing of complementary bases. Figure \(\PageIndex{3}\) shows the two sets of base pairs and illustrates two things. First, a pyrimidine is paired with a purine in each case, so that the long dimensions of both pairs are identical (1.08 nm).
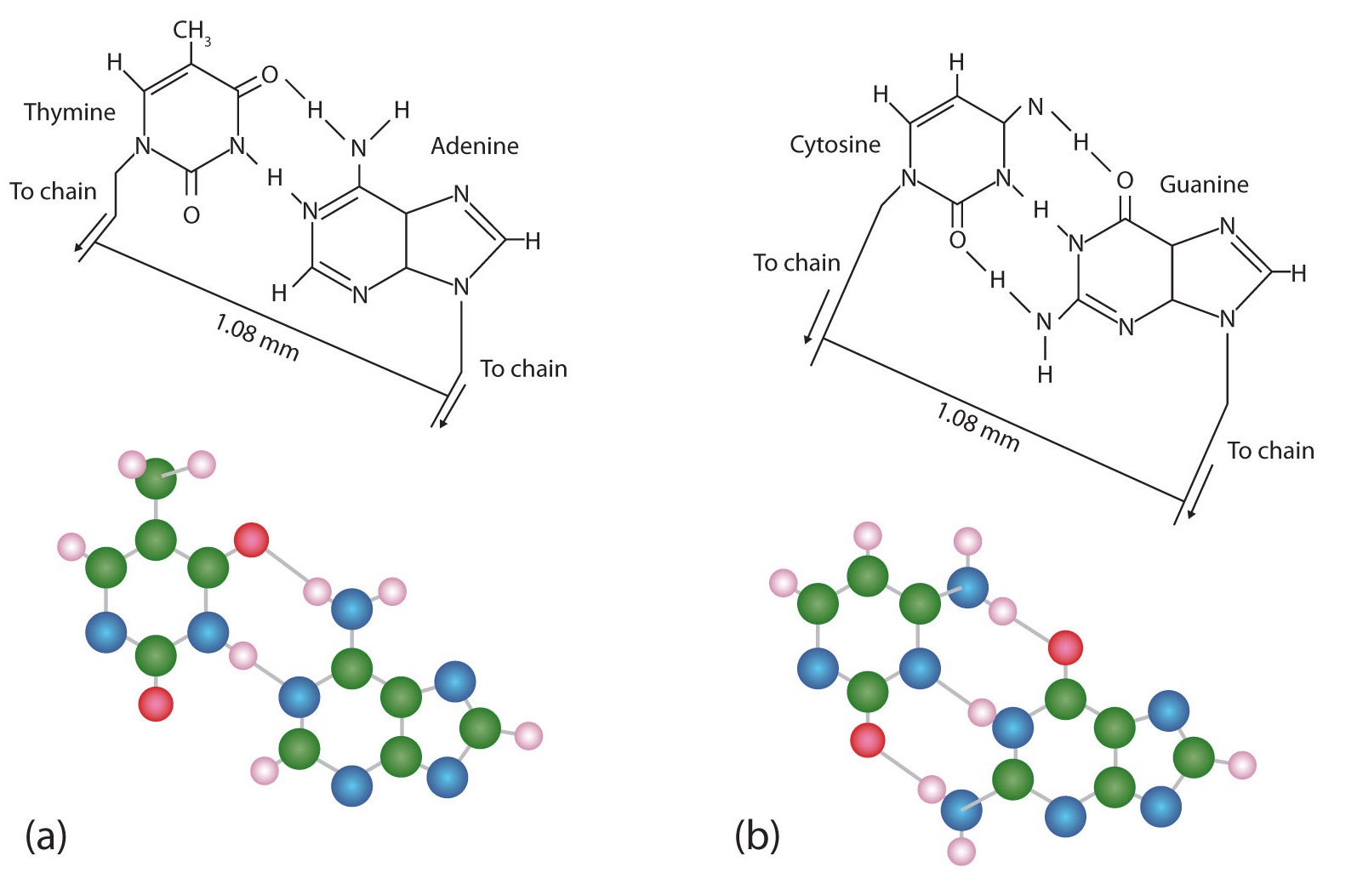
Figure \(\PageIndex{3}\) Complementary Base Pairing. Complementary bases engage in hydrogen bonding with one another: (a) thymine and adenine; (b) cytosine and guanine.
If two pyrimidines were paired or two purines were paired, the two pyrimidines would take up less space than a purine and a pyrimidine, and the two purines would take up more space, as illustrated in Figure \(\PageIndex{4}\). If these pairings were ever to occur, the structure of DNA would be like a staircase made with stairs of different widths. For the two strands of the double helix to fit neatly, a pyrimidine must always be paired with a purine. The second thing you should notice in Figure \(\PageIndex{3}\) is that the correct pairing enables formation of three instances of hydrogen bonding between guanine and cytosine and two between adenine and thymine. The additive contribution of this hydrogen bonding imparts great stability to the DNA double helix.

Figure \(\PageIndex{4}\) Difference in Widths of Possible Base Pairs
Summary
- DNA is the nucleic acid that stores genetic information. RNA is the nucleic acid responsible for using the genetic information in DNA to produce proteins.
- Nucleotides are joined together to form nucleic acids through the phosphate group of one nucleotide connecting in an ester linkage to the OH group on the third carbon atom of the sugar unit of a second nucleotide.
- Nucleic acid sequences are written starting with the nucleotide having a free phosphate group (the 5′ end).
- Two DNA strands link together in an antiparallel direction and are twisted to form a double helix. The nitrogenous bases face the inside of the helix. Guanine is always opposite cytosine, and adenine is always opposite thymine.
Concept Review Exercises
-
- Name the two kinds of nucleic acids.
- Which type of nucleic acid stores genetic information in the cell?
-
What are complementary bases?
-
Why is it structurally important that a purine base always pair with a pyrimidine base in the DNA double helix?
Answers
-
- deoxyribonucleic acid (DNA) and ribonucleic acid (RNA)
- DNA
-
the specific base pairings in the DNA double helix in which guanine is paired with cytosine and adenine is paired with thymine
-
The width of the DNA double helix is kept at a constant width, rather than narrowing (if two pyrimidines were across from each other) or widening (if two purines were across from each other).
Exercises
-
For this short RNA segment,
- identify the 5′ end and the 3′ end of the molecule.
- circle the atoms that comprise the backbone of the nucleic acid chain.
-
write the nucleotide sequence of this RNA segment.
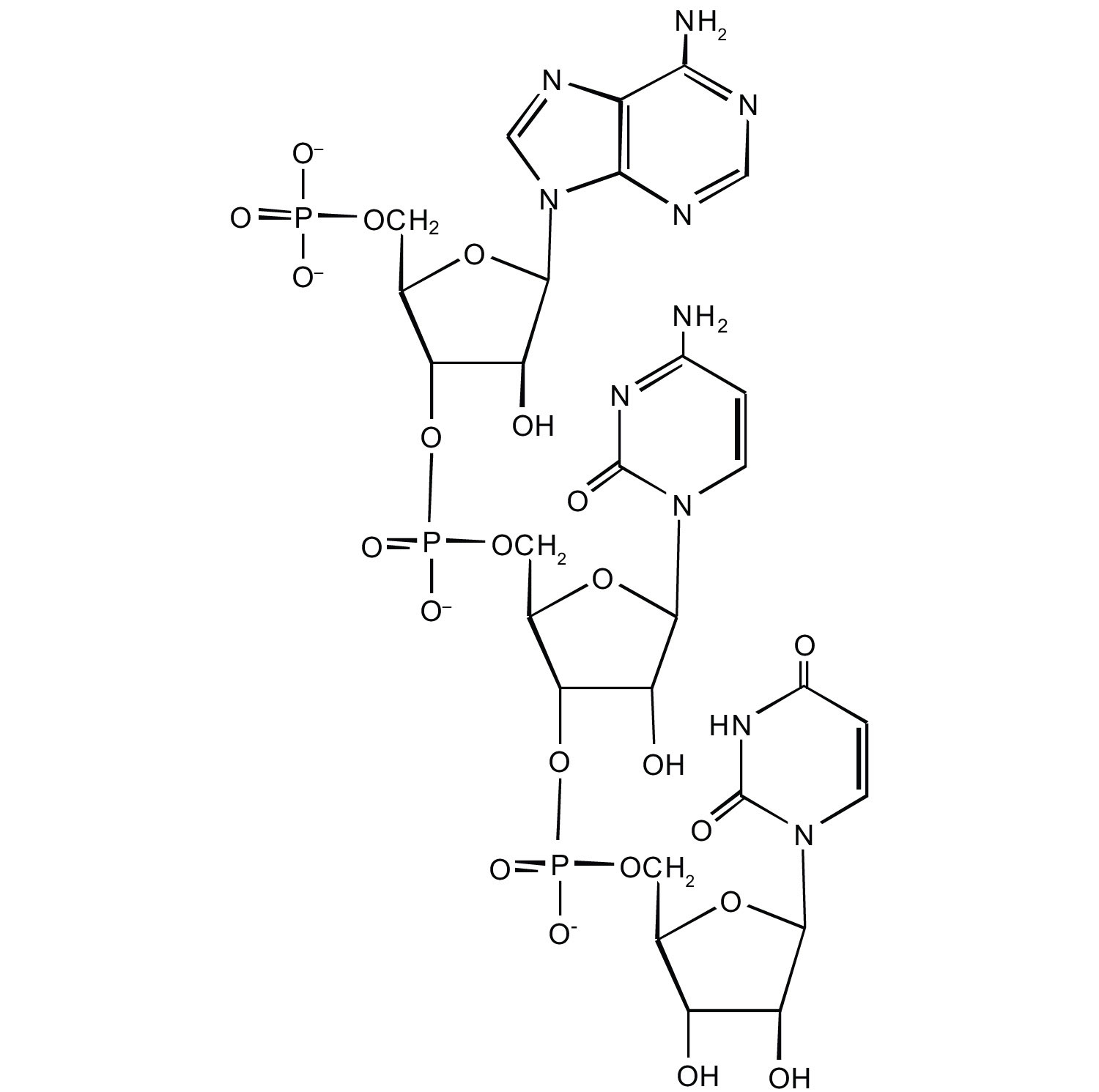
-
For this short DNA segment,
- identify the 5′ end and the 3′ end of the molecule.
- circle the atoms that comprise the backbone of the nucleic acid chain.
-
write the nucleotide sequence of this DNA segment.
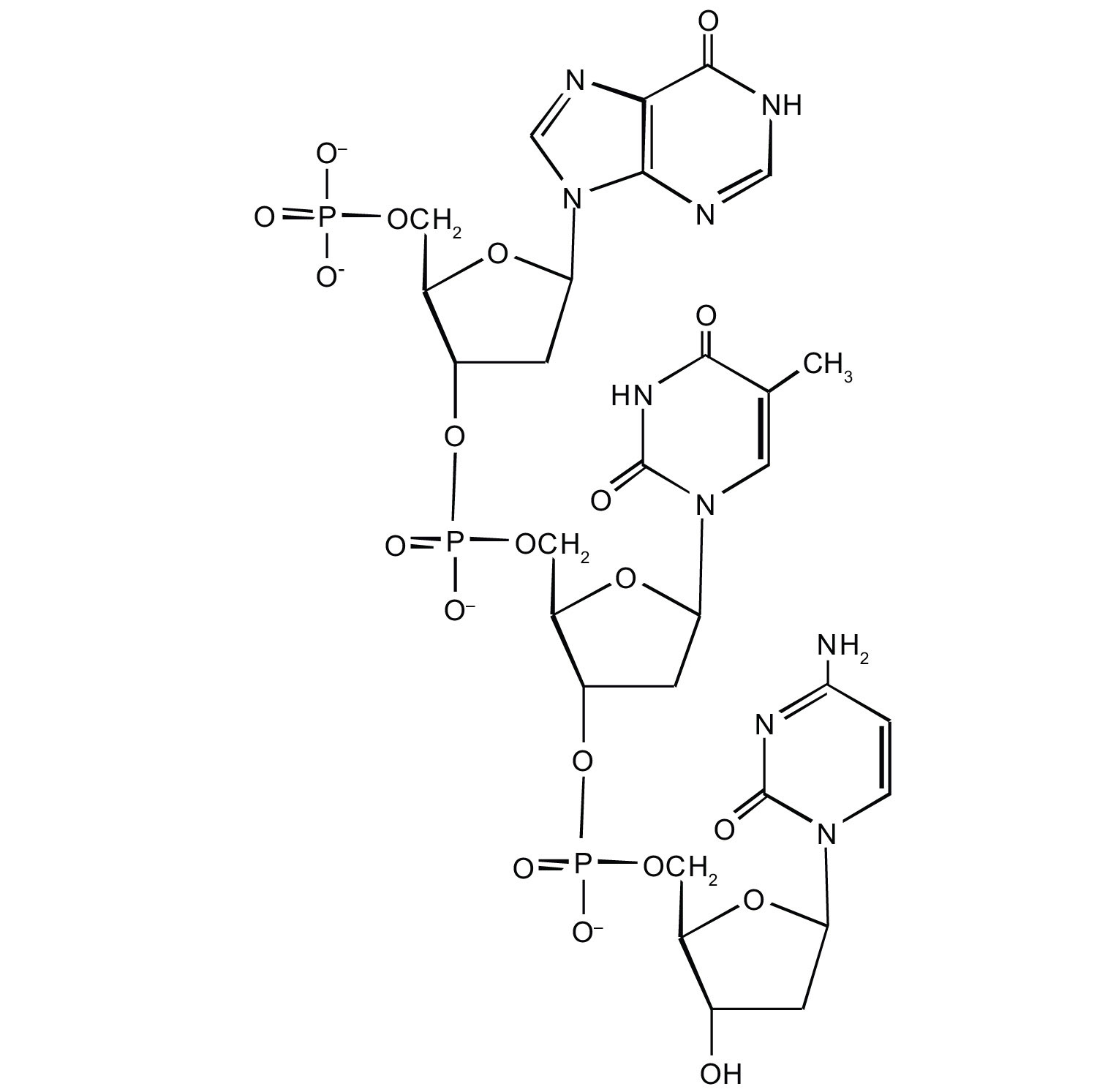
-
Which nitrogenous base in DNA pairs with each nitrogenous base?
- cytosine
- adenine
- guanine
- thymine
-
Which nitrogenous base in RNA pairs with each nitrogenous base?
- cytosine
- adenine
- guanine
- thymine
-
How many hydrogen bonds can form between the two strands in the short DNA segment shown below?
5′ ATGCGACTA 3′ 3′ TACGCTGAT 5′
-
How many hydrogen bonds can form between the two strands in the short DNA segment shown below?
5′ CGATGAGCC 3′ 3′ GCTACTCGG 5′
Answers
-
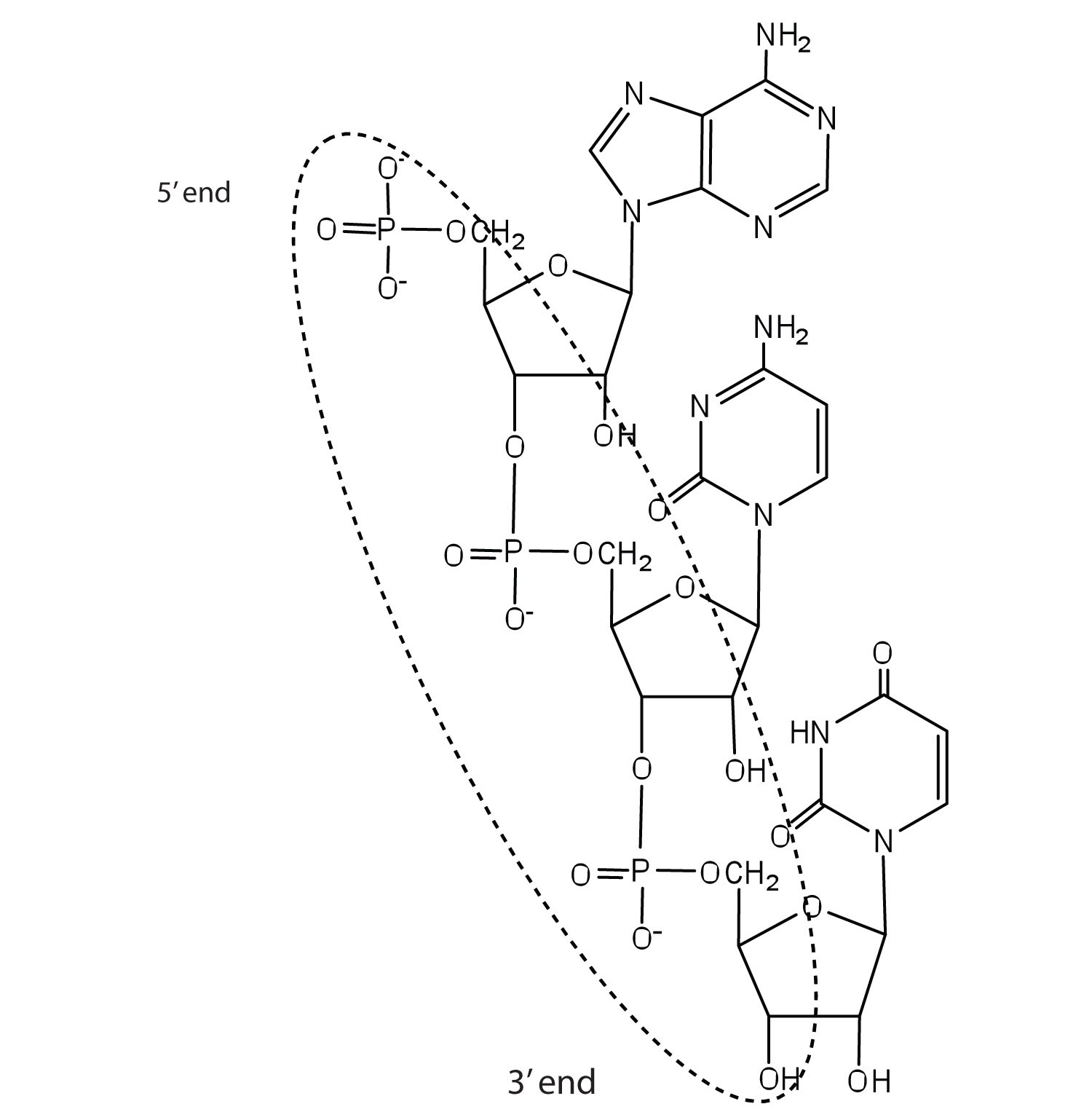
c. ACU
-
- guanine
- thymine
- cytosine
- adenine
-
22 (2 between each AT base pair and 3 between each GC base pair)
- Describe how a new copy of DNA is synthesized.
- Describe how RNA is synthesized from DNA.
- Identify the different types of RNA and the function of each type of RNA.
We previously stated that deoxyribonucleic acid (DNA) stores genetic information, while ribonucleic acid (RNA) is responsible for transmitting or expressing genetic information by directing the synthesis of thousands of proteins found in living organisms. But how do the nucleic acids perform these functions? Three processes are required: (1) replication, in which new copies of DNA are made; (2) transcription, in which a segment of DNA is used to produce RNA; and (3) translation, in which the information in RNA is translated into a protein sequence.
Replication
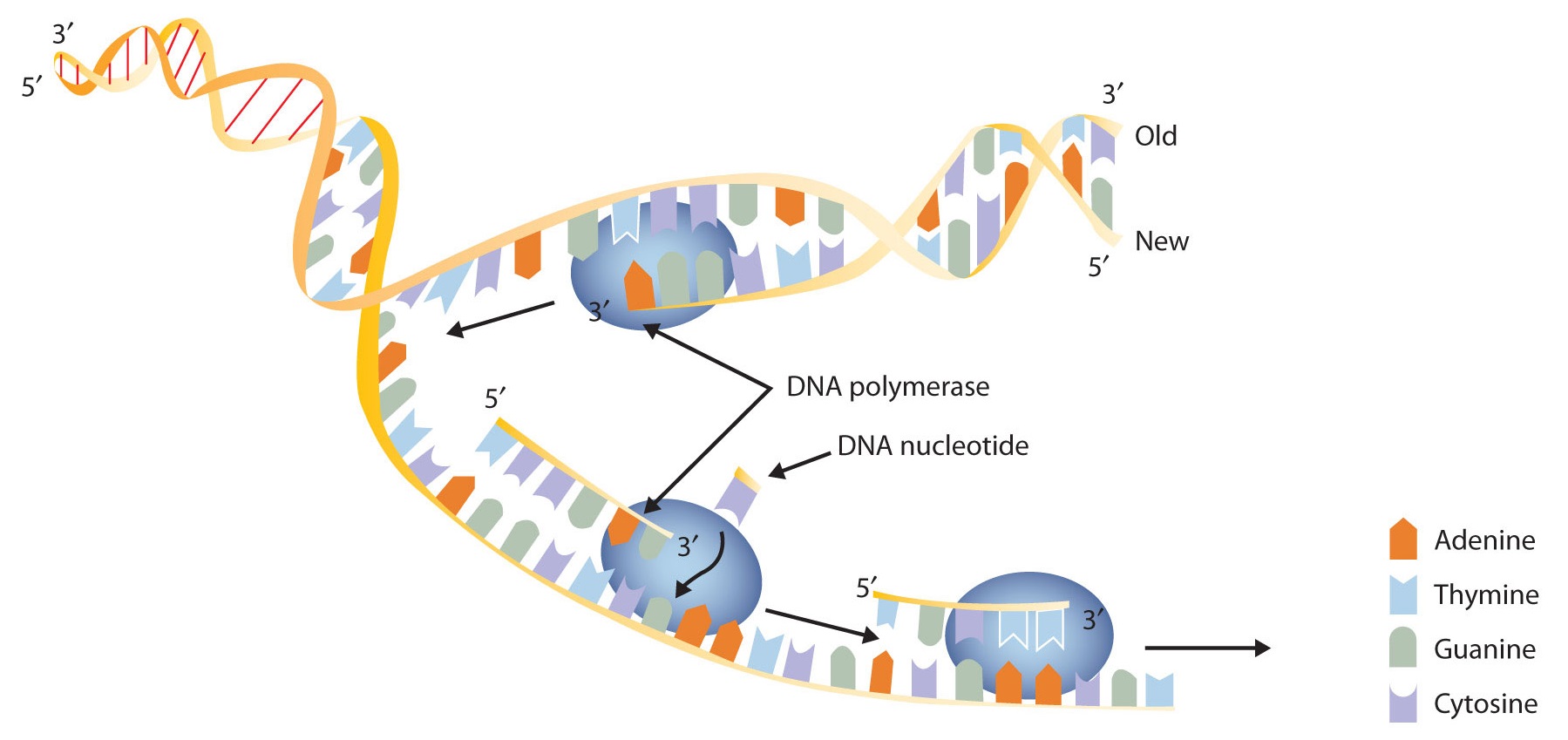
New cells are continuously forming in the body through the process of cell division. For this to happen, the DNA in a dividing cell must be copied in a process known as replication. The complementary base pairing of the double helix provides a ready model for how genetic replication occurs. If the two chains of the double helix are pulled apart, disrupting the hydrogen bonding between base pairs, each chain can act as a template, or pattern, for the synthesis of a new complementary DNA chain.
The nucleus contains all the necessary enzymes, proteins, and nucleotides required for this synthesis. A short segment of DNA is “unzipped,” so that the two strands in the segment are separated to serve as templates for new DNA. DNA polymerase, an enzyme, recognizes each base in a template strand and matches it to the complementary base in a free nucleotide. The enzyme then catalyzes the formation of an ester bond between the 5′ phosphate group of the nucleotide and the 3′ OH end of the new, growing DNA chain. In this way, each strand of the original DNA molecule is used to produce a duplicate of its former partner (Figure \(\PageIndex{1}\)). Whatever information was encoded in the original DNA double helix is now contained in each replicate helix. When the cell divides, each daughter cell gets one of these replicates and thus all of the information that was originally possessed by the parent cell.
A segment of one strand from a DNA molecule has the sequence 5′‑TCCATGAGTTGA‑3′. What is the sequence of nucleotides in the opposite, or complementary, DNA chain?
Solution
Knowing that the two strands are antiparallel and that T base pairs with A, while C base pairs with G, the sequence of the complementary strand will be 3′‑AGGTACTCAACT‑5′ (can also be written as TCAACTCATGGA).
A segment of one strand from a DNA molecule has the sequence 5′‑CCAGTGAATTGCCTAT‑3′. What is the sequence of nucleotides in the opposite, or complementary, DNA chain?
What do we mean when we say information is encoded in the DNA molecule? An organism’s DNA can be compared to a book containing directions for assembling a model airplane or for knitting a sweater. Letters of the alphabet are arranged into words, and these words direct the individual to perform certain operations with specific materials. If all the directions are followed correctly, a model airplane or sweater is produced.
In DNA, the particular sequences of nucleotides along the chains encode the directions for building an organism. Just as saw means one thing in English and was means another, the sequence of bases CGT means one thing, and TGC means something different. Although there are only four letters—the four nucleotides—in the genetic code of DNA, their sequencing along the DNA strands can vary so widely that information storage is essentially unlimited.
Transcription
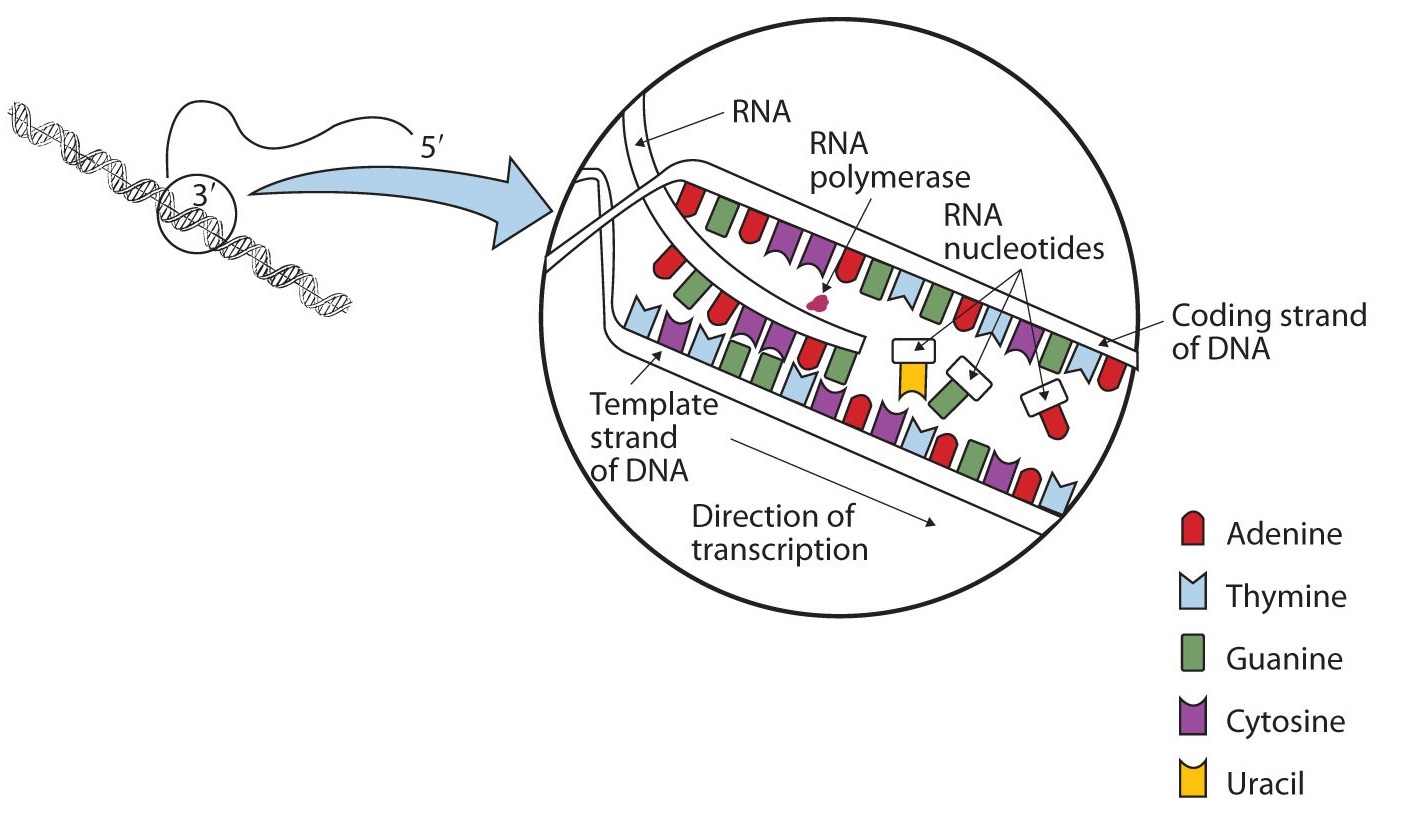
For the hereditary information in DNA to be useful, it must be “expressed,” that is, used to direct the growth and functioning of an organism. The first step in the processes that constitute DNA expression is the synthesis of RNA, by a template mechanism that is in many ways analogous to DNA replication. Because the RNA that is synthesized is a complementary copy of information contained in DNA, RNA synthesis is referred to as transcription. There are three key differences between replication and transcription:
- RNA molecules are much shorter than DNA molecules; only a portion of one DNA strand is copied or transcribed to make an RNA molecule.
- RNA is built from ribonucleotides rather than deoxyribonucleotides.
- The newly synthesized RNA strand does not remain associated with the DNA sequence it was transcribed from.
The DNA sequence that is transcribed to make RNA is called the template strand, while the complementary sequence on the other DNA strand is called the coding or informational strand. To initiate RNA synthesis, the two DNA strands unwind at specific sites along the DNA molecule. Ribonucleotides are attracted to the uncoiling region of the DNA molecule, beginning at the 3′ end of the template strand, according to the rules of base pairing. Thymine in DNA calls for adenine in RNA, cytosine specifies guanine, guanine calls for cytosine, and adenine requires uracil. RNA polymerase—an enzyme—binds the complementary ribonucleotide and catalyzes the formation of the ester linkage between ribonucleotides, a reaction very similar to that catalyzed by DNA polymerase (Figure \(\PageIndex{2}\)). Synthesis of the RNA strand takes place in the 5′ to 3′ direction, antiparallel to the template strand. Only a short segment of the RNA molecule is hydrogen-bonded to the template strand at any time during transcription. When transcription is completed, the RNA is released, and the DNA helix reforms. The nucleotide sequence of the RNA strand formed during transcription is identical to that of the corresponding coding strand of the DNA, except that U replaces T.
A portion of the template strand of a gene has the sequence 5′‑TCCATGAGTTGA‑3′. What is the sequence of nucleotides in the RNA that is formed from this template?
Solution
Four things must be remembered in answering this question: (1) the DNA strand and the RNA strand being synthesized are antiparallel; (2) RNA is synthesized in a 5′ to 3′ direction, so transcription begins at the 3′ end of the template strand; (3) ribonucleotides are used in place of deoxyribonucleotides; and (4) thymine (T) base pairs with adenine (A), A base pairs with uracil (U; in RNA), and cytosine (C) base pairs with guanine (G). The sequence is determined to be 3′‑AGGUACUCAACU‑5′ (can also be written as 5′‑UCAACUCAUGGA‑3′).
A portion of the template strand of a gene has the sequence 5′‑CCAGTGAATTGCCTAT‑3′. What is the sequence of nucleotides in the RNA that is formed from this template?
Three types of RNA are formed during transcription: messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). These three types of RNA differ in function, size, and percentage of the total cell RNA (Table \(\PageIndex{1}\)). mRNA makes up only a small percent of the total amount of RNA within the cell, primarily because each molecule of mRNA exists for a relatively short time; it is continuously being degraded and resynthesized. The molecular dimensions of the mRNA molecule vary according to the amount of genetic information a given molecule contains. After transcription, which takes place in the nucleus, the mRNA passes into the cytoplasm, carrying the genetic message from DNA to the ribosomes, the sites of protein synthesis. Elsewhere, we shall see how mRNA directly determines the sequence of amino acids during protein synthesis.
| Type | Function | Approximate Number of Nucleotides | Percentage of Total Cell RNA |
|---|---|---|---|
| mRNA | codes for proteins | 100–6,000 | ~3 |
| rRNA | component of ribosomes | 120–2900 | 83 |
| tRNA | adapter molecule that brings the amino acid to the ribosome | 75–90 | 14 |
Ribosomes are cellular substructures where proteins are synthesized. They contain about 65% rRNA and 35% protein, held together by numerous noncovalent interactions, such as hydrogen bonding, in an overall structure consisting of two globular particles of unequal size.
Molecules of tRNA, which bring amino acids (one at a time) to the ribosomes for the construction of proteins, differ from one another in the kinds of amino acid each is specifically designed to carry. A set of three nucleotides, known as a codon, on the mRNA determines which kind of tRNA will add its amino acid to the growing chain. Each of the 20 amino acids found in proteins has at least one corresponding kind of tRNA, and most amino acids have more than one.
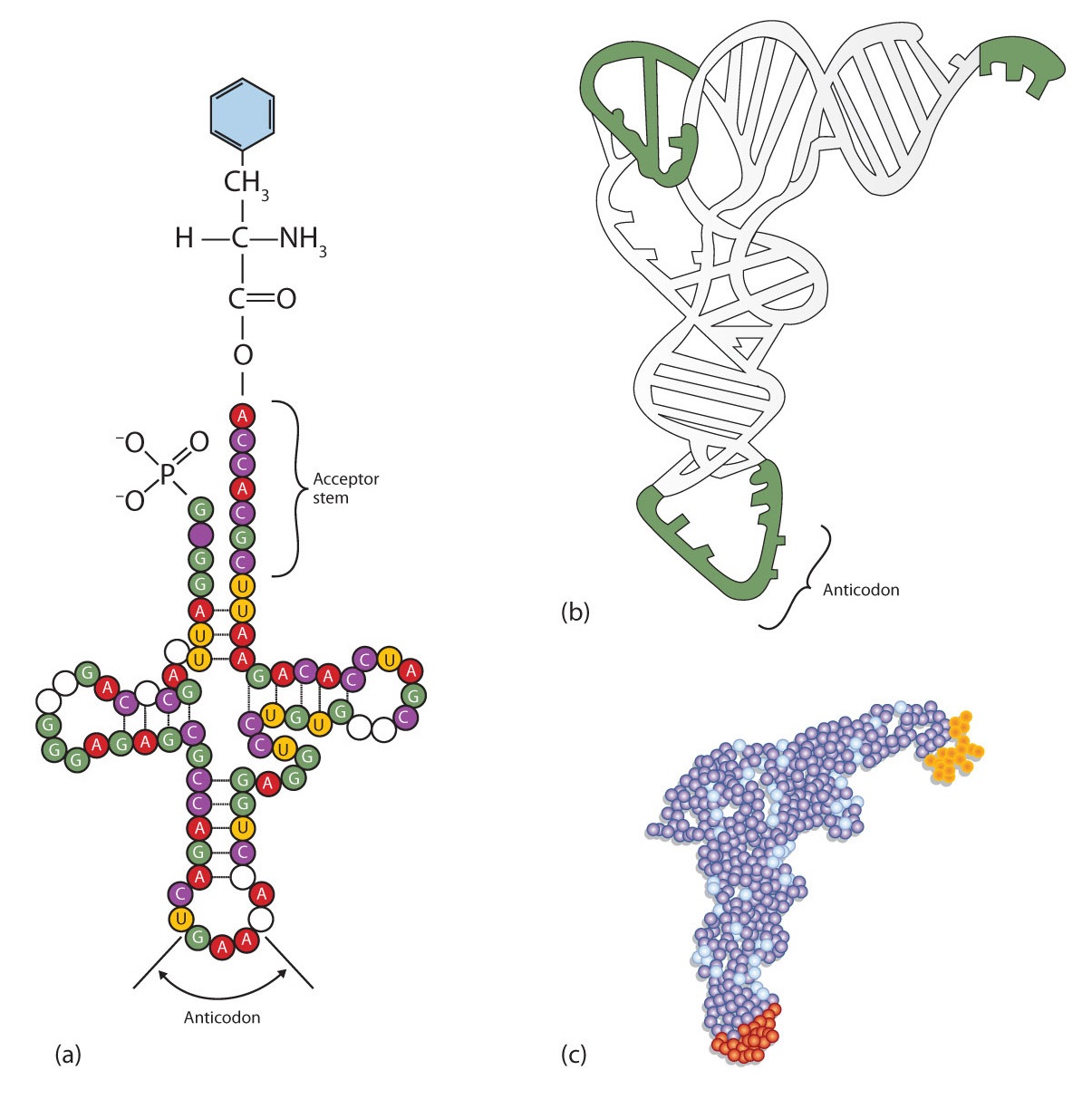
The two-dimensional structure of a tRNA molecule has three distinctive loops, reminiscent of a cloverleaf (Figure \(\PageIndex{3}\)). On one loop is a sequence of three nucleotides that varies for each kind of tRNA. This triplet, called the anticodon, is complementary to and pairs with the codon on the mRNA. At the opposite end of the molecule is the acceptor stem, where the amino acid is attached.
Summary
- In DNA replication, each strand of the original DNA serves as a template for the synthesis of a complementary strand.
- DNA polymerase is the primary enzyme needed for replication.
- In transcription, a segment of DNA serves as a template for the synthesis of an RNA sequence.
- RNA polymerase is the primary enzyme needed for transcription.
- Three types of RNA are formed during transcription: mRNA, rRNA, and tRNA.
- describe the characteristics of the genetic code.
- describe how a protein is synthesized from mRNA.
One of the definitions of a gene is as follows: a segment of deoxyribonucleic acid (DNA) carrying the code for a specific polypeptide. Each molecule of messenger RNA (mRNA) is a transcribed copy of a gene that is used by a cell for synthesizing a polypeptide chain. If a protein contains two or more different polypeptide chains, each chain is coded by a different gene. We turn now to the question of how the sequence of nucleotides in a molecule of ribonucleic acid (RNA) is translated into an amino acid sequence.
How can a molecule containing just 4 different nucleotides specify the sequence of the 20 amino acids that occur in proteins? If each nucleotide coded for 1 amino acid, then obviously the nucleic acids could code for only 4 amino acids. What if amino acids were coded for by groups of 2 nucleotides? There are 42, or 16, different combinations of 2 nucleotides (AA, AU, AC, AG, UU, and so on). Such a code is more extensive but still not adequate to code for 20 amino acids. However, if the nucleotides are arranged in groups of 3, the number of different possible combinations is 43, or 64. Here we have a code that is extensive enough to direct the synthesis of the primary structure of a protein molecule.
Video: NDSU Virtual Cell Animations project animation "Translation". For more information, see VCell, NDSU(opens in new window) [vcell.ndsu.nodak.edu]
The genetic code can therefore be described as the identification of each group of three nucleotides and its particular amino acid. The sequence of these triplet groups in the mRNA dictates the sequence of the amino acids in the protein. Each individual three-nucleotide coding unit, as we have seen, is called a codon.
Protein synthesis is accomplished by orderly interactions between mRNA and the other ribonucleic acids (transfer RNA [tRNA] and ribosomal RNA [rRNA]), the ribosome, and more than 100 enzymes. The mRNA formed in the nucleus during transcription is transported across the nuclear membrane into the cytoplasm to the ribosomes—carrying with it the genetic instructions. The process in which the information encoded in the mRNA is used to direct the sequencing of amino acids and thus ultimately to synthesize a protein is referred to as translation.
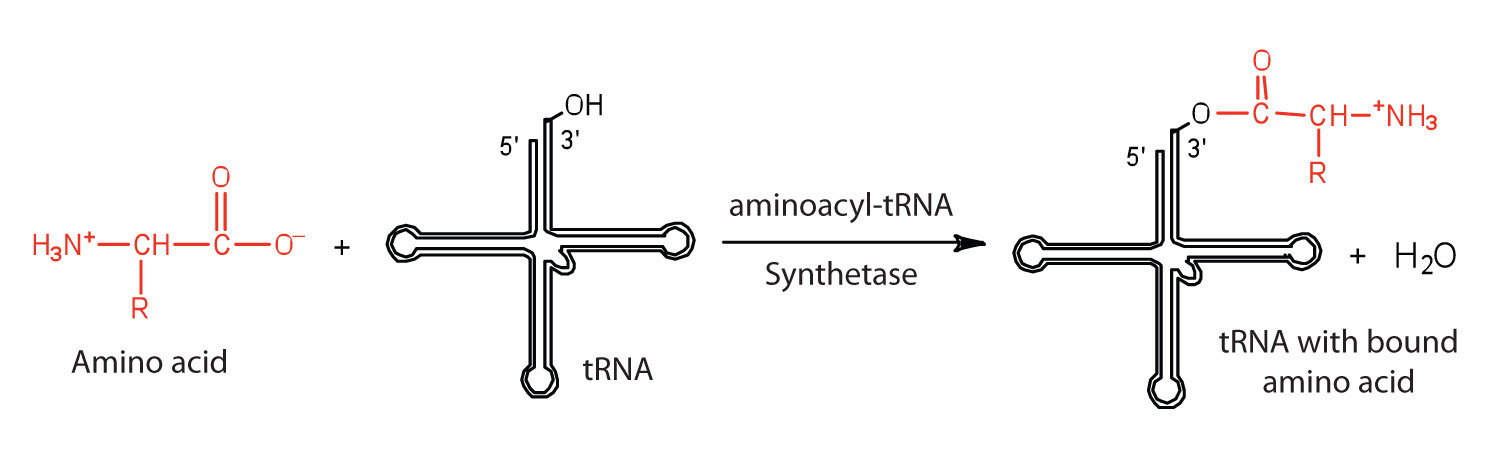
Before an amino acid can be incorporated into a polypeptide chain, it must be attached to its unique tRNA. This crucial process requires an enzyme known as aminoacyl-tRNA synthetase (Figure \(\PageIndex{1}\)). There is a specific aminoacyl-tRNA synthetase for each amino acid. This high degree of specificity is vital to the incorporation of the correct amino acid into a protein. After the amino acid molecule has been bound to its tRNA carrier, protein synthesis can take place. Figure \(\PageIndex{2}\) depicts a schematic stepwise representation of this all-important process.
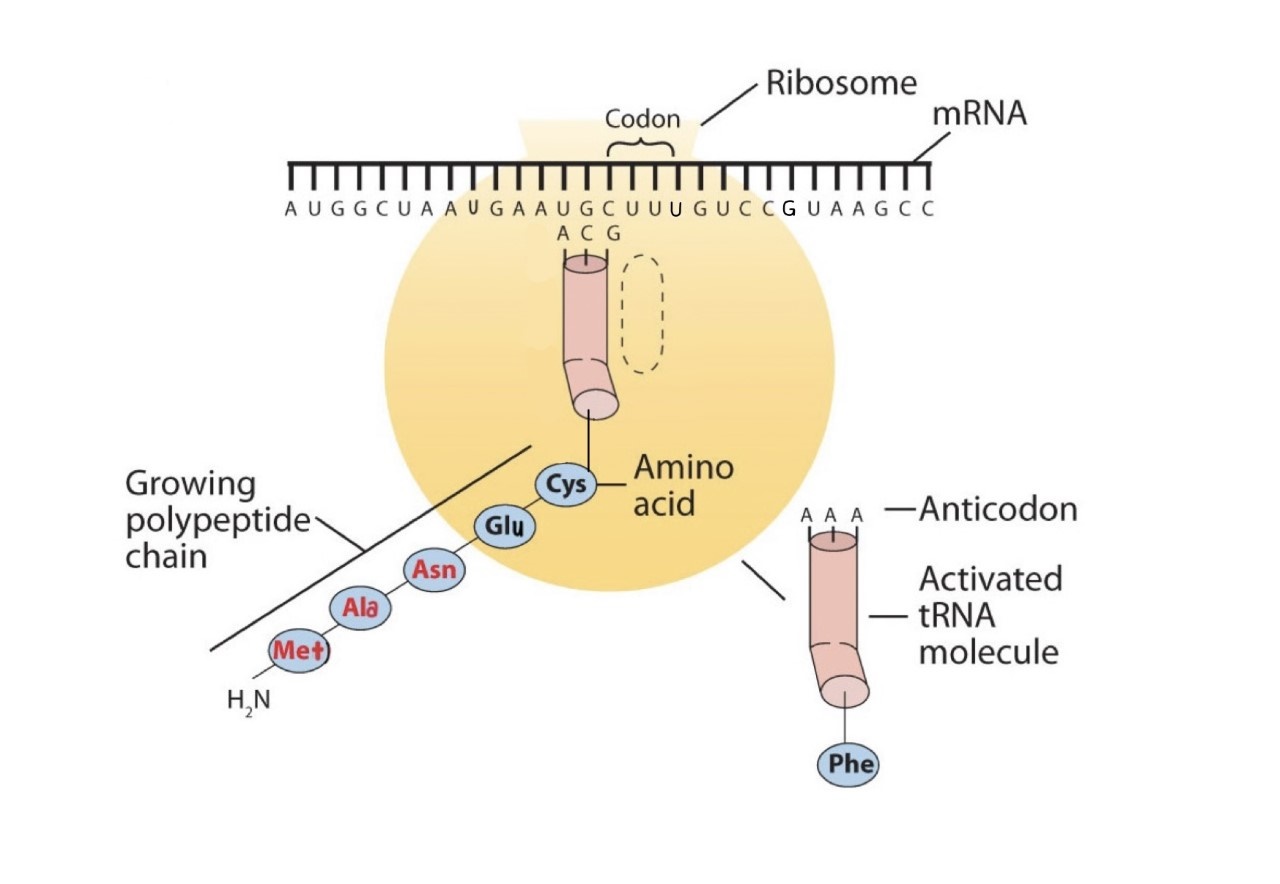
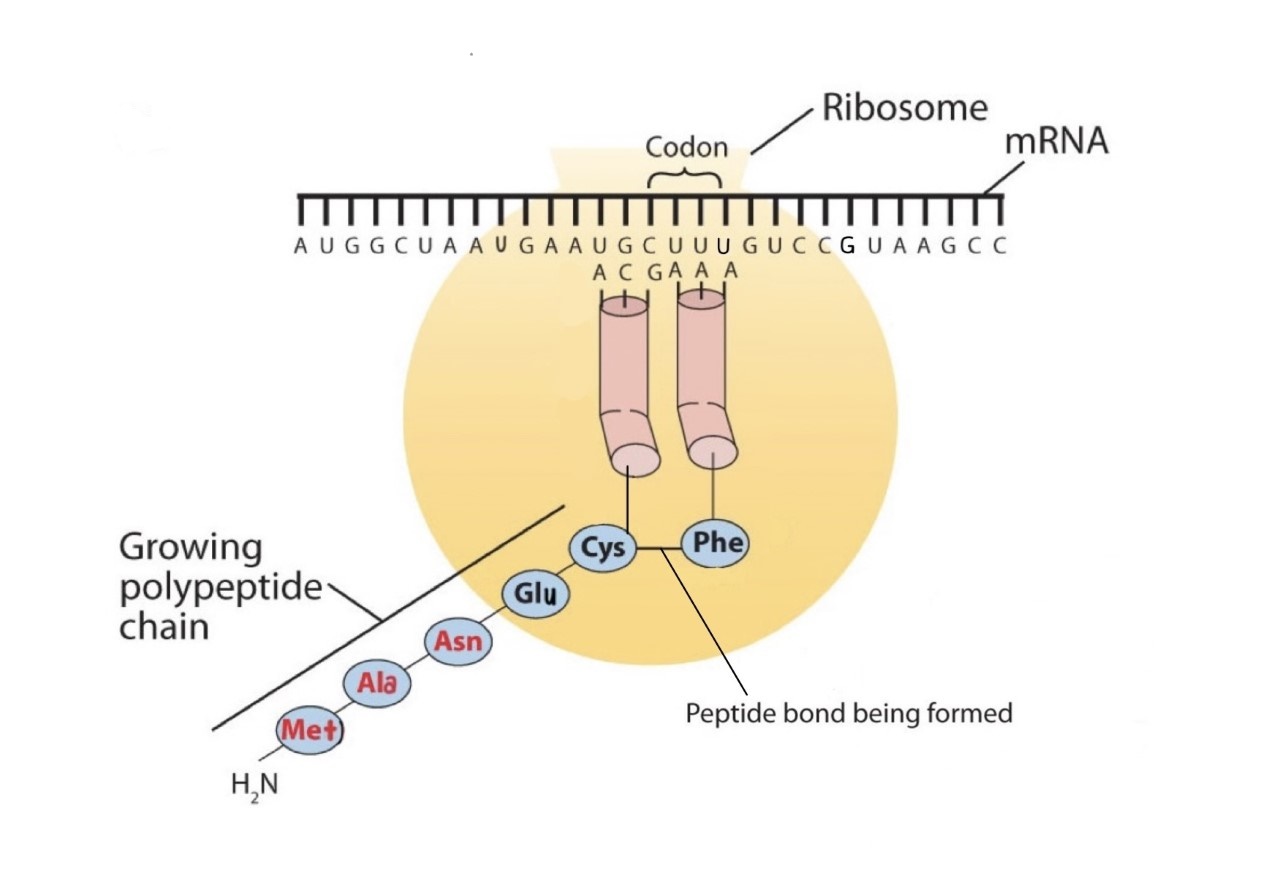
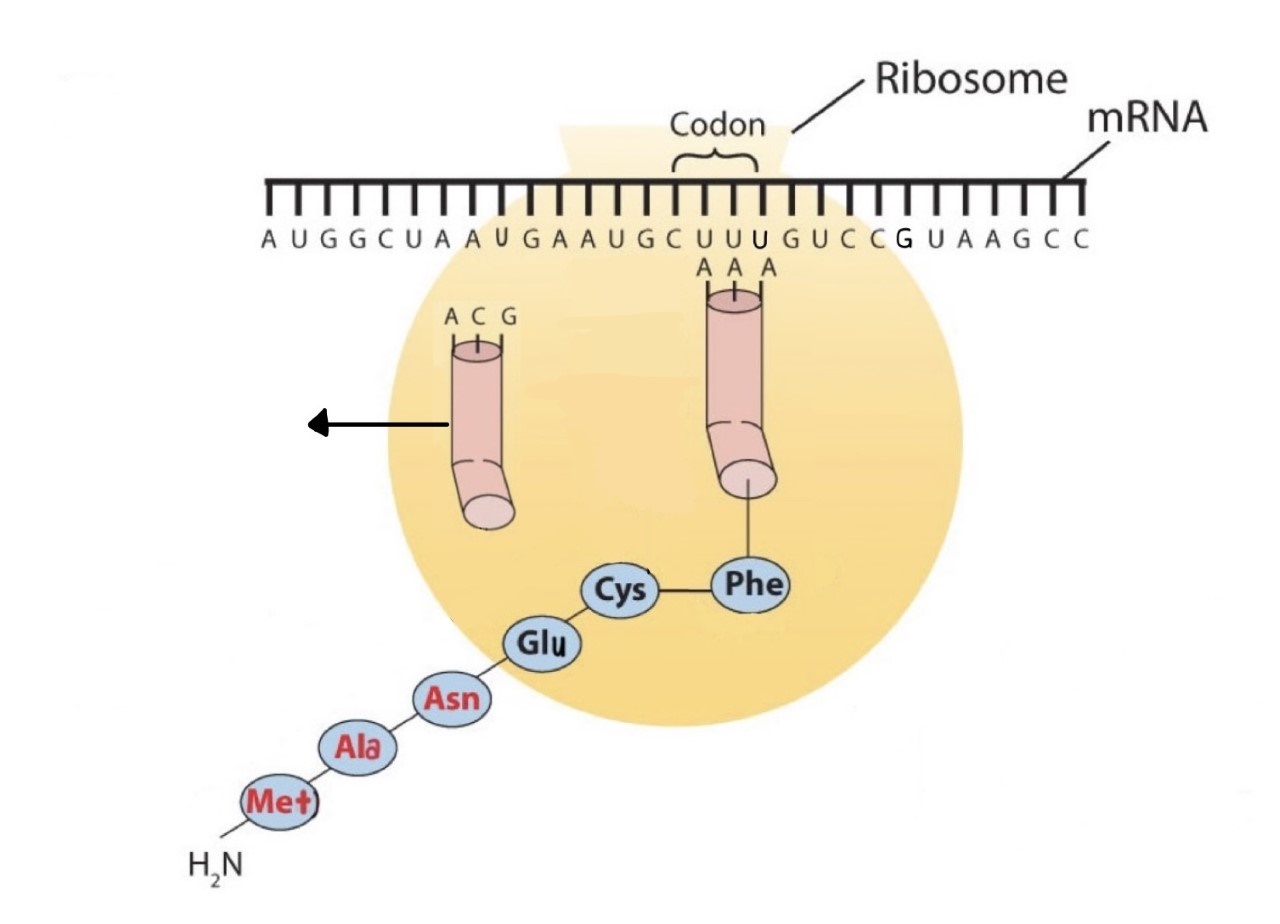
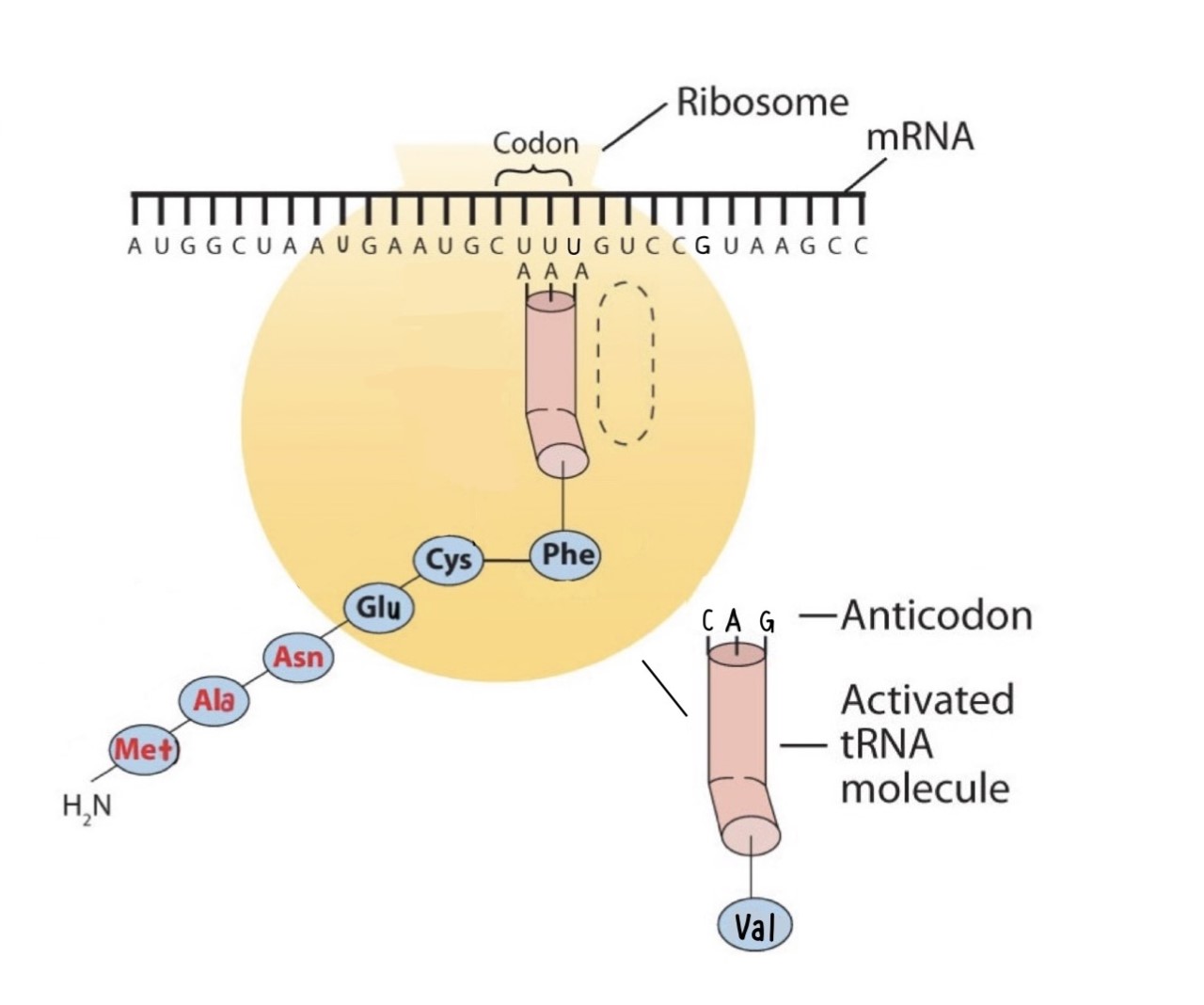
Early experimenters were faced with the task of determining which of the 64 possible codons stood for each of the 20 amino acids. The cracking of the genetic code was the joint accomplishment of several well-known geneticists—notably Har Khorana, Marshall Nirenberg, Philip Leder, and Severo Ochoa—from 1961 to 1964. The genetic dictionary they compiled, summarized in Figure \(\PageIndex{3}\), shows that 61 codons code for amino acids, and 3 codons serve as signals for the termination of polypeptide synthesis (much like the period at the end of a sentence). Notice that only methionine (AUG) and tryptophan (UGG) have single codons. All other amino acids have two or more codons.
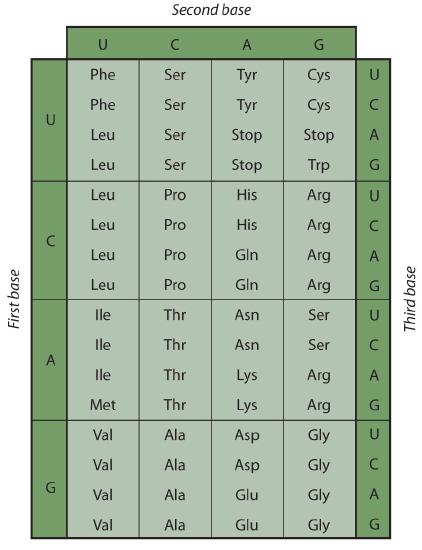
A portion of an mRNA molecule has the sequence 5′‑AUGCCACGAGUUGAC‑3′. What amino acid sequence does this code for?
Solution
Use Figure \(\PageIndex{3}\) to determine what amino acid each set of three nucleotides (codon) codes for. Remember that the sequence is read starting from the 5′ end and that a protein is synthesized starting with the N-terminal amino acid. The sequence 5′‑AUGCCACGAGUUGAC‑3′ codes for met-pro-arg-val-asp.
A portion of an RNA molecule has the sequence 5′‑AUGCUGAAUUGCGUAGGA‑3′. What amino acid sequence does this code for?
Further experimentation threw much light on the nature of the genetic code, as follows:
- The code is virtually universal; animal, plant, and bacterial cells use the same codons to specify each amino acid (with a few exceptions).
- The code is “degenerate”; in all but two cases (methionine and tryptophan), more than one triplet codes for a given amino acid.
- The first two bases of each codon are most significant; the third base often varies. This suggests that a change in the third base by a mutation may still permit the correct incorporation of a given amino acid into a protein. The third base is sometimes called the “wobble” base.
- The code is continuous and nonoverlapping; there are no nucleotides between codons, and adjacent codons do not overlap.
- The three termination codons are read by special proteins called release factors, which signal the end of the translation process.
- The codon AUG codes for methionine and is also the initiation codon. Thus methionine is the first amino acid in each newly synthesized polypeptide. This first amino acid is usually removed enzymatically before the polypeptide chain is completed; the vast majority of polypeptides do not begin with methionine.
Summary
In translation, the information in mRNA directs the order of amino acids in protein synthesis. A set of three nucleotides (codon) codes for a specific amino acid.