Section 1B. What is proteomics?
- Page ID
- 81223

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)The central dogma of molecular biology, DNA to RNA to protein, has given us an explanation of how information encoded by our DNA is translated and used to make an organism. It describes how a gene made of DNA is transcribed by messenger RNA and then translated into a protein by transfer RNA in a complex series of events utilizing ribosomal RNA and amino acids. Although in essence the central dogma remains true, studies of genes and proteins are revealing a complexity that we had never imagined. For example, distinct genes are expressed in different cell types and the physiological state of the cell alters which proteins are produced and at what level. Furthermore, chemical changes (i.e. phosphorylation) to proteins occur after translation and are critical to a protein’s function. The importance and diversity of proteins started a whole new field termed proteomics.
Proteomics is the study of proteins, particularly their structures and functions. This term was coined to make an analogy with genomics. The Human Genome Project, started in 1990 and completed in 2003, sequenced three billion bases in genes (the human genome). The entire set of proteins in existence in an organism throughout its life cycle, or on a smaller scale the entire set of proteins found in a particular cell type under a specific set of conditions is referred to as the proteome.
Proteomics is much more complicated than genomics for several reasons. The genome is a rather constant entity while the proteome differs from cell to cell and is constantly changing through its biochemical interactions with the genome and the environment. Consequently, the proteome reflects the particular stage of development or the current environmental condition of the cell or organism. One organism will have radically different protein expression in different parts of the body, in different stages of its life cycle, and in different environmental conditions. For example, when E. coli cells are grown under conditions of elevated temperature a class of proteins known as heat shock proteins are upregulated. Many members of this group perform a chaperone function by stabilizing new proteins to ensure correct folding or by helping to refold proteins that were damaged by the cell stress. Ultimately, the comparison of proteomes of healthy and diseased tissues may identify the molecular nature of a disease and provide potential new targets for drug development. The field of proteomics also presents many analytical challenges when compared to genomics. In DNA there are only four nucleotide bases with similar molecular weights and properties. In a proteome there are thousands of different proteins with a wide range of concentrations, molecular weights, and properties.
Proteomics was initially defined as the effort to catalog all the proteins expressed in all cells at all stages of development. That definition has now been expanded to include the study of protein functions, protein-protein interactions, cellular locations, expression levels, and post-translational modifications of all proteins within all cells and tissues at all stages of development. It is hypothesized that a large amount of the non-coding DNA in the human genome functions to regulate protein production, expression levels, and post-translational modifications. It is regulation of our complex proteomes, rather than our genes, that makes us different from simpler organisms with a similar number of genes. An international collaboration of scientists in the human Proteome Project (HPP) is working to characterize all 20,300 genes of the known genome and generate a map of the protein based molecular architecture of the human body. Completion of this project will enhance understanding of human biology at the cellular level and lay a foundation for development of diagnostic, prognostic, therapeutic, and preventive medical applications.
1. Define the term proteome.
2. Define the term proteomics.
3. Why is the analysis of proteins in a cell more difficult than sequencing DNA?
4. What types of questions can be answered by studying the proteome?
Read the following research paper to learn how the field of proteomics can be useful in the treatment of cancer.
Comparative proteomics of oral cancer cell lines: identification of cancer associated proteins, Karsani et al, Proteome Science, 2014, 12:3. doi:10.1186/1477-5956-12-3 (Open access journal)
1. What was goal of the scientific study reported in the paper?
2. Why would a study of the change in oral cancer proteins add to our understanding of the disease?
3. Refer to the results and discussion section and Figure 1 to answer the following questions.
a. How were the proteins in the healthy and cancerous cells separated and detected?
b. How many individual protein spots were resolved on the silver stained gels?
c. How many protein spots exhibited a significant difference in abundance from normal cells to cancerous cells?
4. Table 1 is a list of proteins with different abundances in the cancer cell line.
(The section in this module on peptide mass mapping describes how the identity of the protein in the gel spot was determined.)
Examine the data for two structural proteins: Stathmin (STMN1) and myosin regulatory light chain-2 (ML12A).
What is the change in abundance for each protein? Can this change be visualized from the image of the spot?
How is the change quantified?
5. The simplified 2D gel shown represents the proteins from a healthy cell line.
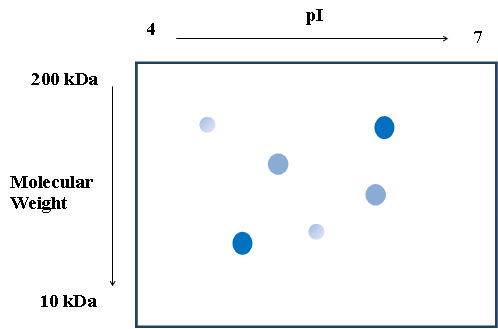
Draw a new 2D gel which could represent the changes in protein expression that occur in a cancerous cell line.