
7.3: Proteins
- Page ID
- 288511
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Amino acids
There are 20 naturally occurring amino acids. They have the general format shown below.

Credit: Amino Acid Structure by TechGuy78
These molecules are called amino acids because they all share two functional groups in common: an amine group (-NH2) and a carboxylic acid group (-COOH). With the exception of proline, they all have the same backbone: NH2-CH-COOH. They each have a different R- group or side chain attached to the first carbon atom.
The twenty naturally occurring amino acids (plus selenocysteine) are shown below. Can you identify the backbone in each image? The rest of the molecule is the side chain.
Credit: Amino Acids by Dan Cojocari
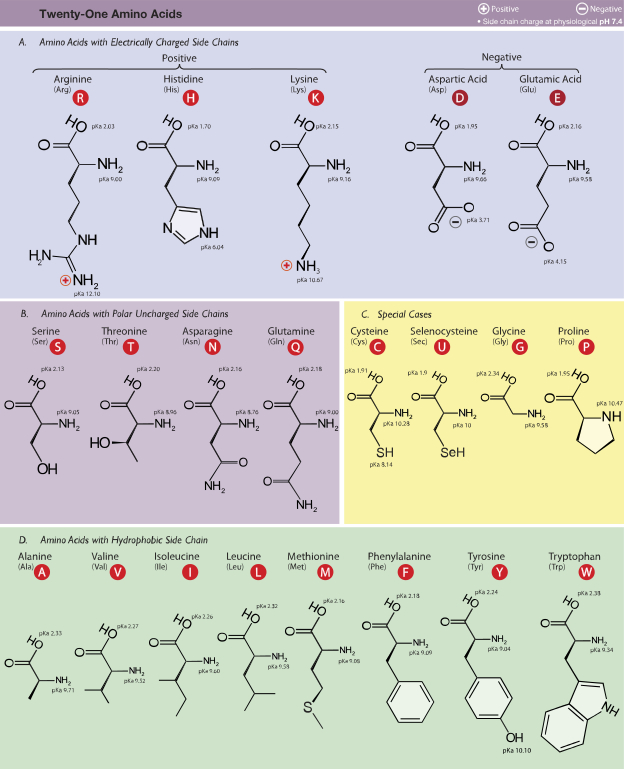
There is a wide variety of side chains and they give the amino acids different properties. Some are hydrophobic (from the Greek for water and fear) and cannot dissolve in water because they are nonpolar. Others are hydrophilic (from the Greek for water and love) and can dissolve in water. This affects protein folding (discussed below) because hydrophobic amino acids tend to be found on the inside of proteins whereas hydrophilic proteins tend to be found on the outer edges of proteins (near aqueous solutions).
The Peptide Bond
Amino acids are monomers that form proteins, naturally occurring polymers. The bond between amino acids is called a peptide bond. It forms between the carboxylic acid group of one amino acid and the amine group of another amino acid. Thus, the backbones of the amino acids get connected to one another and the side chains do not connect to one another. The resulting chain, or protein, looks like a charm bracelet, a long backbone with various different attachments at each amino acid. The general form of the reaction is:
amino acid 1 + amino acid 2 → dipeptide + water
This reaction is called condensation because water is produced. To see where the water comes from, examine the structures involved:
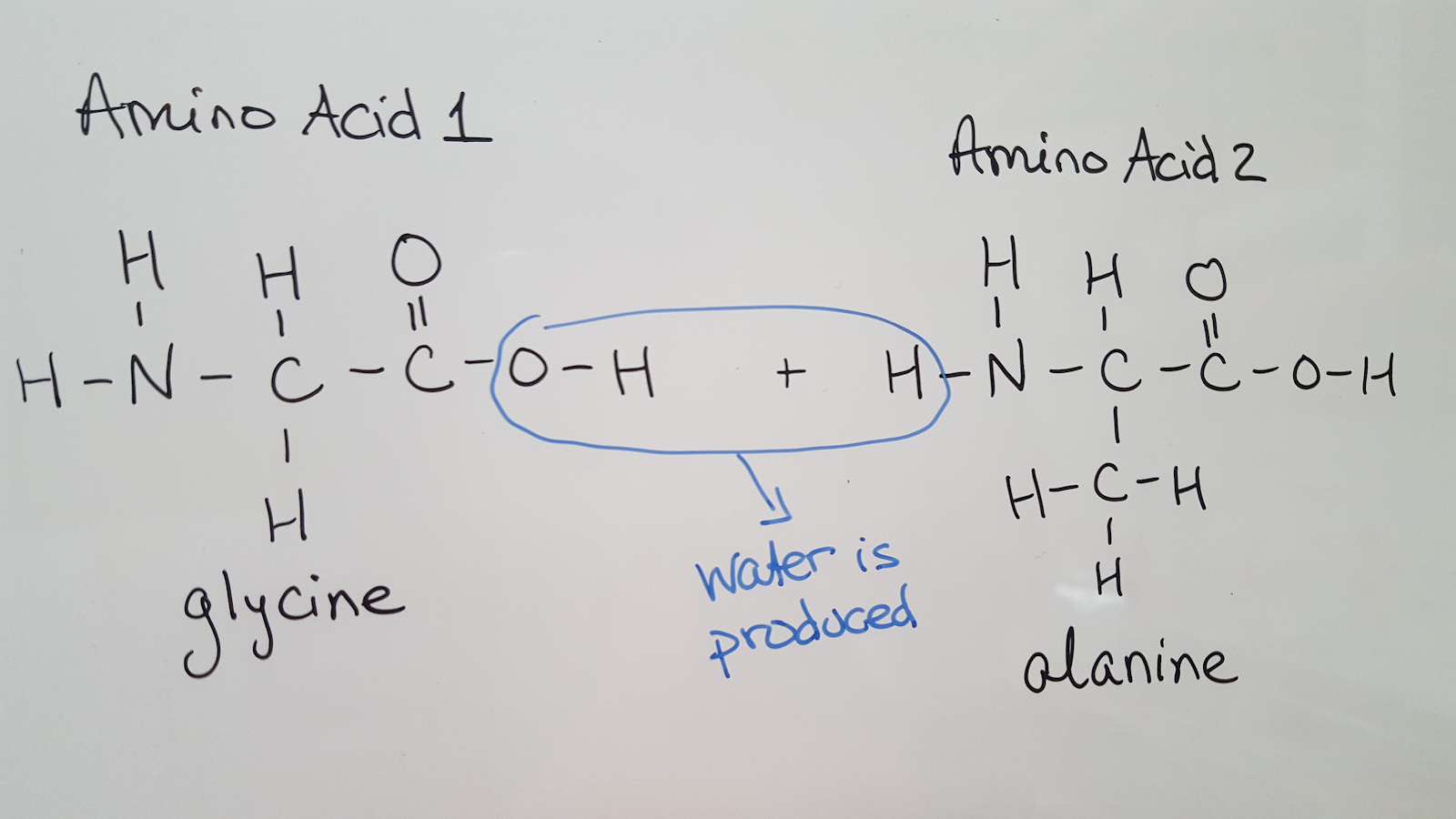
When the reaction occurs, the carboxylic acid group loses the OH and the amine group loses an H. Together, these form water. The peptide bond forms between the carbon of amino acid 1 and the nitrogen of amino acid 2:
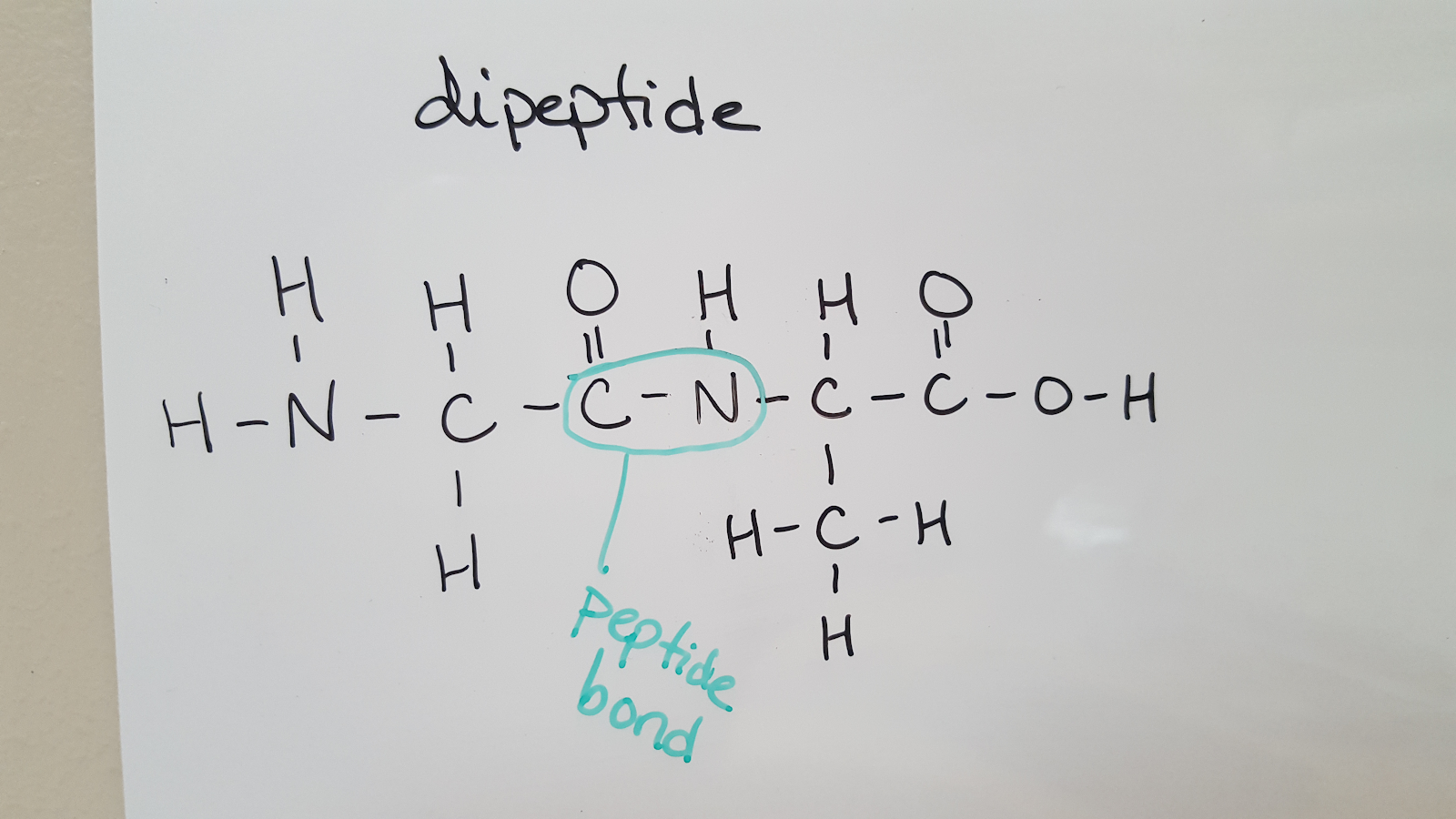
When this reaction repeats, additional amino acids are added to the chain. Because water is removed, the backbone of a protein has the pattern N-C-C-N-C-C-N-C-C (there is an amine group on the first amino acid and a carboxylic acid group on the last amino acid). Therefore, you can determine how many amino acids are in a peptide by counting how many times the -N-C-C- pattern repeats.
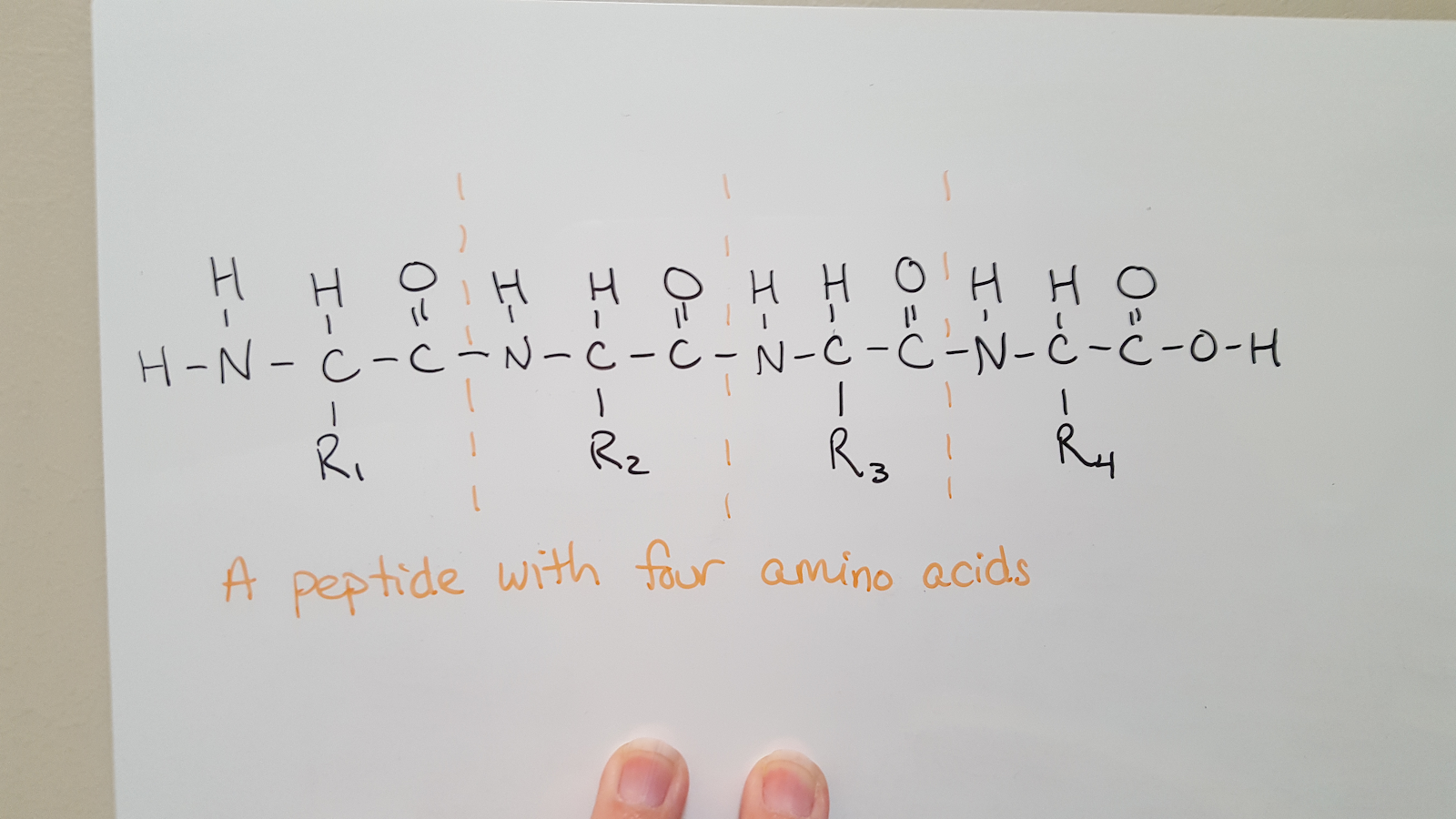
Peptide sequences are always written with the N-terminus, the amine end, on the left and the C-terminus, the carboxylic acid end, on the right.
Protein Structure
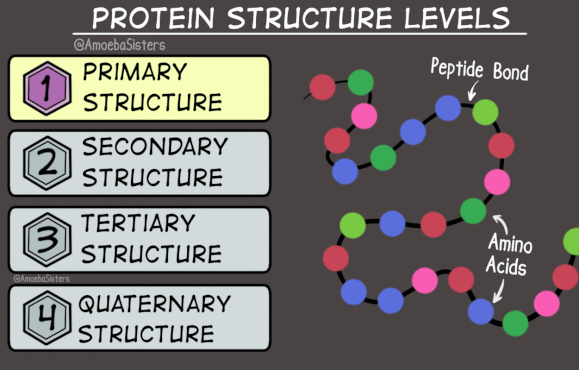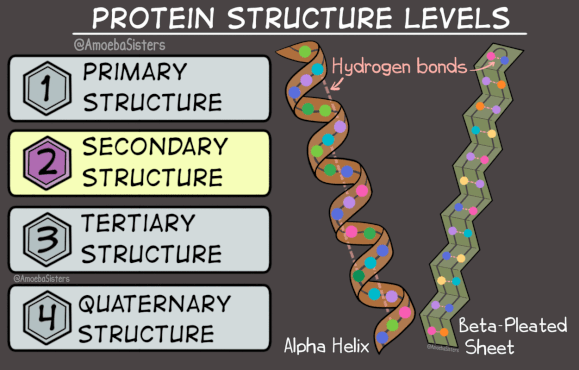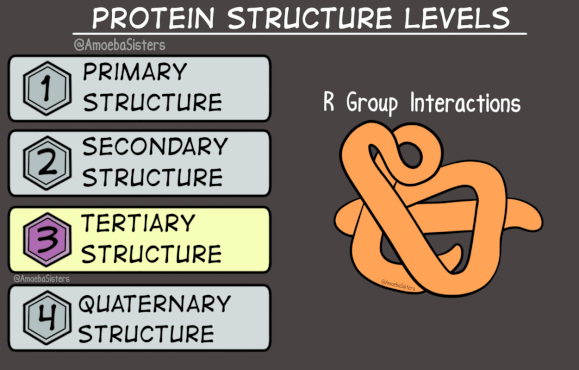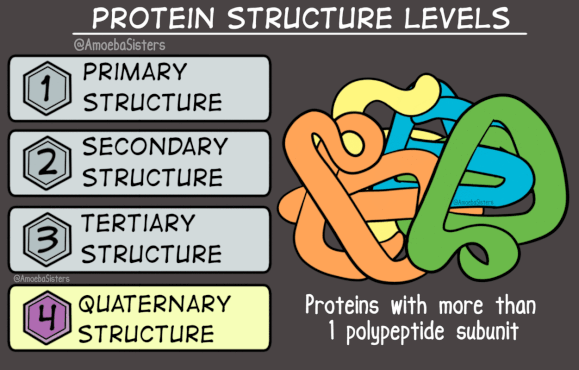
Because proteins are very large molecules, we can think about their structure at four different levels. Sometimes we are interested in the order in which the amino acids are connected in the chain. This is the primary structure, 1°, of the protein.
-Trp-Tyr-Ser-Ala-Leu-
It lists the amino acids present in the correct order (from N-terminus to C-terminus), but tells nothing about the three-dimensional shape of the protein.
The next level of protein structure is the secondary structure, 2°. This indicates a local 3D structure, or in other words, interactions that are occurring in a portion of the protein. It describes the structure in only a portion of the protein chain. Therefore, a protein may contain many secondary structures. Some common secondary structures are the alpha helix (⍺-helix) and the beta-sheet (ꞵ-sheet). In these secondary structures hydrogen bonds hold different parts of the protein backbone together in a spiral (the alpha helix) or in strands that go back and forth (the beta sheet).


Credit: Pi Helix by WillowW
On the left above is an alpha helix where the pink lines indicate hydrogen bonds between N-H and C=O portions of the backbone. To the right is a portion of a beta-sheet where hydrogen bonds are indicated by dashed lines that connect two portions of the same protein (it folds over along itself). This pattern continues with the protein backbone folding again and again as shown using a ribbon diagram in the image on the right below.


Credit: Protein Image from OPM database by Andrei Lomize
The figure to the left above shows an entire protein. The backbone in portions of the structure is shown as a ribbon to emphasize the local, or secondary, structure: an alpha-helix. Other portions of the backbone are shown as tubes. Similarly, the figure on the right shows a beta-sheet with the portions of the backbone that are hydrogen bonding represented with ribbons.
Thus, you can see that the secondary structure does not indicate the overall shape of a protein, just the structure in a particular portion of the backbone. The tertiary structure (3°) does refer to the entire 3D shape of a protein strand. Because the tertiary structure of each protein is unique, a collaborative effort has been made to create a record of all known protein structures. The result is the Protein Data Bank.
It may seem as if no additional levels of structure would be needed. However, some proteins are composed of multiple strands interacting with one another. The overall arrangement of these strands is the quaternary structure (4°). Many proteins do not have a quaternary structure because they consist of only one chain. Hemoglobin is an example of a protein that does have a quaternary structure because it has four strands. Its quaternary structure can be seen below.
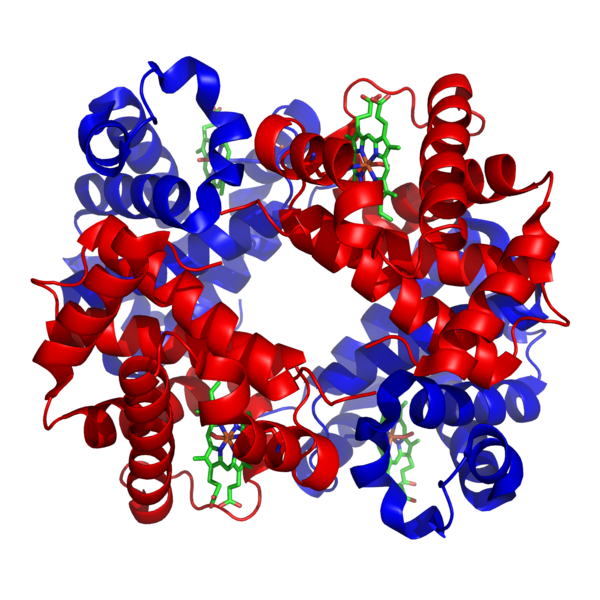
Credit: Structure of haemoglobin by Richard Wheeler.
The four strands that make up this protein are called subunits and are shown in red and blue in the picture.
Enzymes
Enzymes are proteins that act as catalysts. They speed up reactions that would otherwise take too long within the body. This is preferable to another method of speeding up reactions: increasing the temperature! Instead, mammals keep their body temperatures regulated and enzymes perform well in this range.
There are many different enzymes in the body because they each catalyze specific chemical reactions. Name of enzymes typically end with the suffix -ase and the rest of the name often provides a clue as to the function of the enzyme, e.g. the enzyme lactase breaks lactose down into two simple sugars and DNA polymerase is used in the synthesis of DNA (a polymer).
Enzymes provide a location for one or more reactants to bind while the reaction is occurring and lower the activation energy of the reaction. In these reactions the reactants are called substrates and the location on the enzyme where the reaction occurs is called the active site.
The picture below shows the interaction between substrates and an enzyme for a reaction that follows the induced-fit model. In the induced-fit model of enzyme catalysis, when the substrate(s) bind in the active site the protein changes structure slightly to fit around the substrate(s).
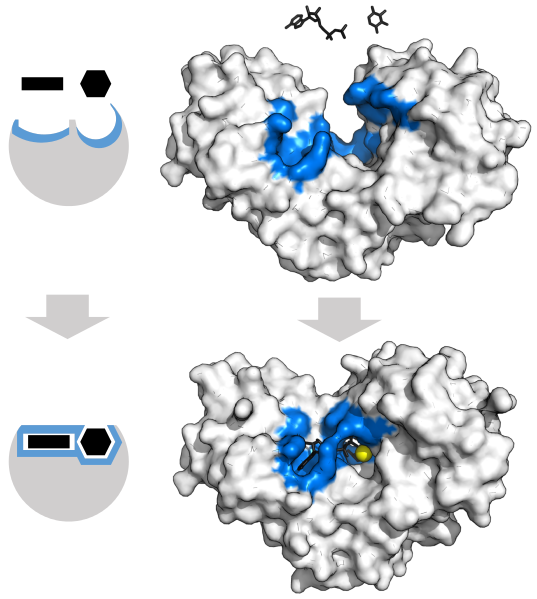
Credit: Hexokinase induced fit by Thomas Shafee
The top of the diagram is the “before” picture where the enzyme and two substrate molecules are initially separate from one another. In both the block diagram on the left and the molecular model on the right the active site is highlighted in blue and the substrate molecules are shown in black. In the bottom half of the diagram, the substrates are bound to the enzyme and the active site has closed around them. After the reaction is completed (not shown) the product will leave the active site and the enzyme will return to its original conformation to be used again by new substrate molecules. Thus enzymes, like all catalysts, are not consumed in chemical reactions and can be reused by other substrate molecules.
Another model of enzyme function is the lock-and-key model. This model is similar to the induced-fit model in that the substrate(s) bind to an active site in the enzyme, but there is no change in the structure of the enzyme. The substrate(s) fit into the active site like a key fits into a lock.
In order to control reactions occurring in the body, inhibitors can be produced. Inhibitors prevent enzymes from catalyzing chemical reactions, for instance when enough product has already been produced. There is a delicate balance between the amounts of substrates, products, and inhibitors so that the body functions properly.
Some inhibitors disrupt the chemical reactions by stealing the active site. These are called competitive inhibitors and they have a shape similar to the substrate so that they can fit into the active site. There are a limited number of enzyme molecules present and whenever an inhibitor molecule binds with one there is one less opportunity for the substrate to react. Increasing the concentration of inhibitor molecules slows down the reaction whereas increasing the concentration of substrate molecules overcomes the inhibition. Thus, as concentrations of substrates and inhibitors change, the amount of product being produced changes.
Other inhibitors do not bind to the active site, they have a totally different shape than the substrates that they inhibit.