
1.3: Experimental Error and Statistics
- Page ID
- 60445
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Density, Experimental Error and Data Analysis
Purpose
The purpose of this laboratory is to collect datasets that will be used to show the random and systematic errors associated with any measurement. The student will make learn about data analysis. Density measurements will be used as the first example. Density is chosen because it is a familiar concept and this allows the student to focus on the new concepts of experimental error in this laboratory.
Introduction
Density, and extensive and intensive properties
Mass and volume are extensive properties. Extensive properties depend on the amount of substance present in a sample. Usually an intensive property results if two extensive properties are divided. An intensive property is a characteristic of a substance and does not depend on the amount present.
Density (d) is an example of an intensive property derived from two extensive properties, mass (m) and volume (V).
\[d=\frac{m}{V} \nonumber \]
Although there are many ways to measure density for specialized applications, in this laboratory we will measure density by measuring the mass and volumes of samples and then calculating the density.
Experimental Error
No measurement is perfectly exact and in fact all measurements have random errors systematic errors. Suppose that the same measurement was repeated a large number of times. Random error prevents the measurement from giving you the same value every time. Figure 1 is a distribution that shows the general result for a repeated measurement. The x-axis shows the measured values as the experiment was repeated. The y-axis shows the number of times the experiment yielded a particular measured value.
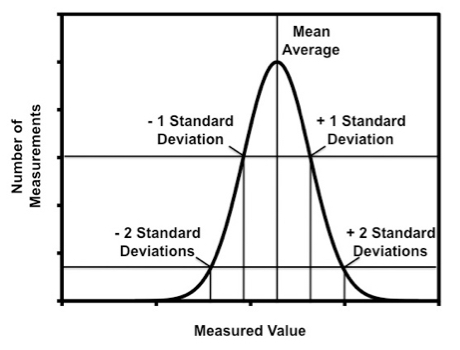
Random error leads to the Gaussian (or normal distribution) shown in Figure 1. The mean average is the most frequently measured value. The mean, \(\overline{x}\), is given by:
\[\overline{x}=\frac{\sum x_{i}}{N} \nonumber \]
where: xi are the measured values and N is the total number of measurements. The standard deviation of the mean, \(\sigma\), is given by:
\[\sigma = \sqrt{\frac{\sum(x_{i}-\overline{x})^{2}}{N-1}} \nonumber \]
An apparatus or a procedure for a measurement may have systematic errors. The difference between random and systematic error is that systematic errors can lead to bias whereas random errors contribute to imprecision. For example the measurement may have a bias that tends to yield higher or lower values than the “true” value, Figure 2.
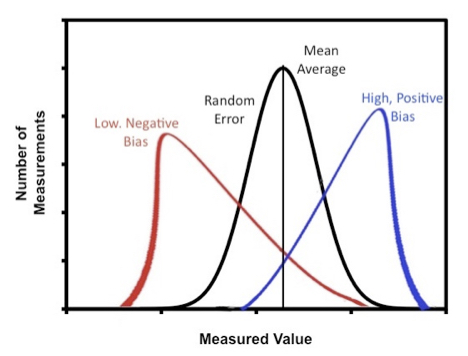
Systematic errors may be fixed (e.g. constant in magnitude) or proportional in magnitude to concentration or other experimental variables. Since the averaging of of a very large number of replicate measurements will reduce the random error, the total error for a system of measurements will tend towards the systematic error as the number of replicate measurements increases. You may be able to test this result based on a comparison of all data generated by the class.
Experimental Procedure
You will measure the volume and mass of three substances that were chosen to be somewhat difficult. Your grade does not depend on getting the “right” density but it does depend on your learning about measurements. The substances are navy beans, Styrofoam and ice.
1) Navy Beans: Each group will take a clean and dry 250 ml beaker, weigh it on a top-loading balance and record its mass. Remove the beaker from the balance and then weigh it again. Weigh the beaker a total of 5 times. Ask yourself if you always get the same results.
Add 50 ml of beans to the beaker, weigh it and record the total mass. Pour out the beans back to the stock of beans and stir the stock of beans so that you will not be weighing all the same beans again. Measure another 50 ml of beans and weigh. Do not try to get the same mass as the first by adding, subtracting, shaking the beaker… doing these kinds of things introduces systematic bias and will ruin the experiments. Repeat this procedure for a total of 10 times.
Repeat for 100 ml of beans. Repeat this for a total of 10 times with volumes of 100 ml of beans.
Repeat for 150 ml of beans. Repeat this for a total of 10 times with volumes of 150 ml of beans.
Repeat for 200 ml of beans. Repeat this for a total of 10 times with volumes of 200 ml of beans.
2) Styrofoam: Repeat the procedure above but substitute Styrofoam for the navy beans.
3) Ice: Repeat the procedure above but substitute ice for the navy beans. Make sure that you use a paper towel to dry the ice before weighing it and do not handle it with your fingers (Why not?). This is difficult but do the best you can to remove the water. You may find that there is some systematic bias in the ice measurements. Describe the sources and types of error in your lab report.
4) Data Pooling: We will pool our data across all groups and be sure to submit your data to the instructors at the end of the lab period.
Data Analysis – Error and Distributions
The data will be provided in an Excel spreadsheet and you will calculate the density of the beans, Styrofoam and ice from the measurements. Keep four significant digits in these calculations.
Calculate the average mass of the beaker. The mean average, \(\overline{x}\), is given by:
\[\overline{x}=\frac{\sum x_{i}}{N} \nonumber \]
where: xi are the measured values and N is the total number of measurements. Determine the standard deviation of the mass measurements for the empty beaker with the formula,
\[\sigma = \sqrt{\frac{\sum(x_{i}-\overline{x})^{2}}{N-1}} \nonumber \]
Calculate the density for all of the mass measurements from the following formula,
\[d=\frac{m_{i}-m_{b}}{V} \nonumber \]
where \(m_i\) is the measured total mass, \(m_b\) is the mass of the empty beaker and \(V\) is the volume (50, 100, 150 and 200 ml). For the mass of the beaker use its average mass. You will get a set of densities for navy beans, Styrofoam and ice. For example a sample dataset for navy beans is given below.
| Volume (ml) |
Mass (g) |
Density (g / ml) |
Volume (ml) |
Mass (g) |
Density (g / ml) |
|---|---|---|---|---|---|
| 0.000 | 114.0 | ||||
| 50.00 | 154.0 | 0.800 | 150.0 | 248.0 | 0.893 |
| 50.00 | 154.2 | 0.804 | 150.0 | 242.2 | 0.855 |
| 50.00 | 160.2 | 0.924 | 150.0 | 239.2 | 0.835 |
| 50.00 | 158.2 | 0.884 | 150.0 | 248.2 | 0.895 |
| 50.00 | 158.0 | 0.880 | 150.0 | 242.3 | 0.855 |
| 50.00 | 152.1 | 0.762 | 150.0 | 240.5 | 0.843 |
| 100.0 | 197.0 | 0.830 | 200.0 | 276.8 | 0.814 |
| 100.0 | 204.2 | 0.902 | 200.0 | 280.4 | 0.832 |
| 100.0 | 199.8 | 0.858 | 200.0 | 282.0 | 0.840 |
| 100.0 | 195.9 | 0.819 | 200.0 | 282.2 | 0.841 |
| 100.0 | 201.5 | 0.875 | 200.0 | 283.8 | 0.849 |
| 100.0 | 203.1 | 0.891 | 200.0 | 279.2 | 0.826 |
Calculate the mean average and the standard deviation for the densities of the beans, Styrofoam and ice. For example, the average and the standard deviation of the limited dataset above are 0.85 g/ml and 0.038 g/ml, respectively.
Next take the density for each substance and sort it (there is an Excel command for this). Below is an example from the sample dataset.
| Density (g / ml) |
Density (g / ml) |
|---|---|
| 0.762 | 0.849 |
| 0.800 | 0.855 |
| 0.804 | 0.855 |
| 0.814 | 0.858 |
| 0.819 | 0.875 |
| 0.826 | 0.880 |
| 0.830 | 0.884 |
| 0.832 | 0.891 |
| 0.835 | 0.893 |
| 0.840 | 0.895 |
| 0.841 | 0.902 |
| 0.843 | 0.924 |
This is the same data as above. The data as been sorted from low to high values.
Sort the data into bins consisting of equal data ranges. See the example below. You will have to adjust the size range of the bin to get a good understanding of the distribution. Describe the thought process used to determine your bin sizes. WARNING: We do NOT expect that everyone thinks the exact same way.
| Density Range (g / ml) |
Number of Values in the Range |
|---|---|
| <0.799 | 1 |
| 0.80-0.8299 | 5 |
| 0.83-0.8599 | 10 |
| 0.86-0.8899 | 3 |
| 0.89-0.9199 | 4 |
| >0.92 | 1 |
Make a plot of the density range and the number of values similar to Figure 3 for each substance. Fit a polynomial curve to the bars to see the distribution better.
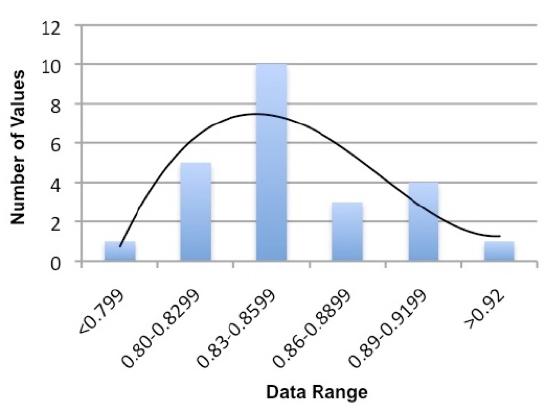
Figure 3. A plot of the distribution derived from Table 3. Note that it is not too far from the normal distribution. There may be a small systematic negative bias in the measurements.
Data Analysis – Part 2 – Analysis by Linear Regression
Read the handout “Error, Accuracy, Precision and Linear Regression”. There is another method to treat the measurements that usually results in more accurate results. This method is linear regression.
An Excel spreadsheet for linear regression is supplied. An advantage of the spreadsheet is that it gives the best fit slope, intercept and their standard deviations. The standard deviations are not available from the standard version of Excel, you have to buy an extra Excel statistical package to have them.
Make three copies of the original spreadsheet for linear regression and save the original in case you mess up one of the copies. Paste all of the volume and mass measurements for each substance into a copy of the Excel spreadsheet. Include values made with the empty beaker and enter the volume as zero for these.
Copy the regression plots along with the best fit slope, intercept and their standard deviations into your laboratory report. You should add labels to the axes of the plots, Figure 4. The slope is the density for each substance and the standard deviation of the slope is the standard deviation of the density. Compare the values calculated by linear regression with the results from Part 1. Is the standard deviation of the density larger or smaller than the one calculated in Part 1?
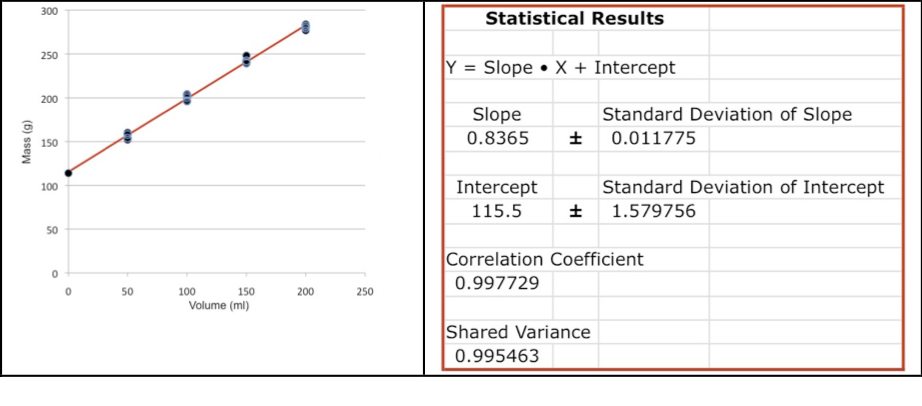
Figure 4: A plot of the linear regression of all data from Table 1 showing the best-fit line. The statistical results from the spreadsheet for linear regression are shown on the right.
Part 2 - Calibration of a UV-Visible Spectrometer
Purpose
In this laboratory you will learn the general theory of calibration. To perform the calibrations you need to understand the concepts of significant figures, measurement error, accuracy, precision, propagation of errors, graphing and linear regression.
Introduction
It is easy to buy any number of measuring devices: thermometers, scales to measure your weight, watches and timers, laboratory instruments etc. To often, at least at home, people just trust the numbers coming out of the measuring devices. Chemists make measurements with some devices that they have used for centuries, such as volumetric glassware (pipettes, graduated cylinders, etc.) and chemical balances and with modern spectrometers. In a medical laboratory or in a hospital the results may be disastrous if the numbers are not accurate. How do can you know that the measurements correspond to reality? Calibration of the measurement device is required. Calibration is the process that correlates an instrument’s response with known standards. In this laboratory you will perform a calibrations of a UV-Vis spectrometer.
Calibration of a UV-Visible Spectrometer
- First you will use an Ocean Optics visible spectrometer and a hydrogen discharge lamp. Turn on the hydrogen lamp and examine its spectrum. Use the green cursor to read the wavelengths of the hydrogen lines.
- One of the spectra should be read at a low enough integration time so that none of the lines “peak out”.
- The second spectra should be recorded at a higher integration time so that you can see lines with lower intensity.
- Each group will make their own spectral measurements.
- Repeat this procedure for argon and mercury using the same spectrometer that you used for your group’s hydrogen spectra.
- Make one calibration curve for your spectrometer using your data that includes both your hydrogen and argon data.
Make a table in Excel with your wavelengths measured lines and the known lines. Note that there will be differences between the wavelengths of the peaks as measured by the spectrometer and their known wavelengths. For hydrogen the known lines are 656.3, 486.1, 434.1 and 410.2 nm. You can check these spectral lines and find the ones for argon at: http://physics.nist.gov/PhysRefData/ASD/index.html. Note that H I and Ar I are the atoms of H and Ar, respectively.
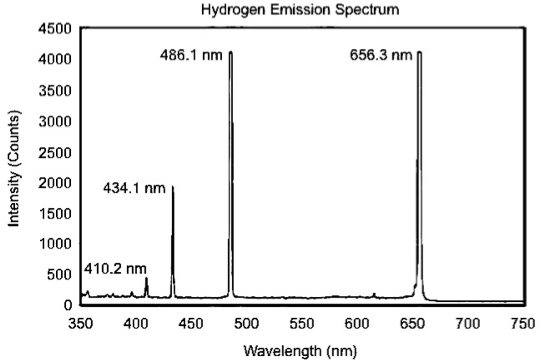

- Plot the points and determine slope and intercept as you have done in the precious sections. It is strongly suggested that you use the known lines as the “y-axis” and your measured lines as the “x-axis”.
- Copy the hydrogen lines into the Linear Regression Spreadsheet and calculate the slope, standard deviation of slope, intercept, standard deviation of intercept, the correlation coefficient and the shared variance for these data. The equation that you will get is the following:
Calibrated Wavelengths = slope * measure wavelength + intercept
- Copy the statistical results and the plot of the calibration curve for the wavelength scale into your laboratory report in the Results section.
See Also: http://www.astronomyknowhow.com/hydrogen-alpha.htm
Report
You may combine this section with the first part on density to create one report. Comment on the bias of all the measurements.
The Linear Regression Spreadsheet is Available at:
A weighted least squares regression spreadsheet is available at: