
28.3 Replication of DNA
- Page ID
- 91081
Objectives
After completing this section, you should be able to describe, very briefly, the replication of DNA.
Make certain that you can define, and use in context, the key terms below.
- replication
- semiconservative replication
Notice that the objective for this section requires only that you be able to describe the replication process briefly.
New cells are continuously forming in the body through the process of cell division. For this to happen, the DNA in a dividing cell must be copied in a process known as replication. The complementary base pairing of the double helix provides a ready model for how genetic replication occurs. If the two chains of the double helix are pulled apart, disrupting the hydrogen bonding between base pairs, each chain can act as a template, or pattern, for the synthesis of a new complementary DNA chain.
The nucleus contains all the necessary enzymes, proteins, and nucleotides required for this synthesis. A short segment of DNA is “unzipped,” so that the two strands in the segment are separated to serve as templates for new DNA. DNA polymerase, an enzyme, recognizes each base in a template strand and matches it to the complementary base in a free nucleotide. The enzyme then catalyzes the formation of an ester bond between the 5′ phosphate group of the nucleotide and the 3′ OH end of the new, growing DNA chain. In this way, each strand of the original DNA molecule is used to produce a duplicate of its former partner (Figure 28.3.1). Whatever information was encoded in the original DNA double helix is now contained in each replicate helix. When the cell divides, each daughter cell gets one of these replicates and thus all of the information that was originally possessed by the parent cell.
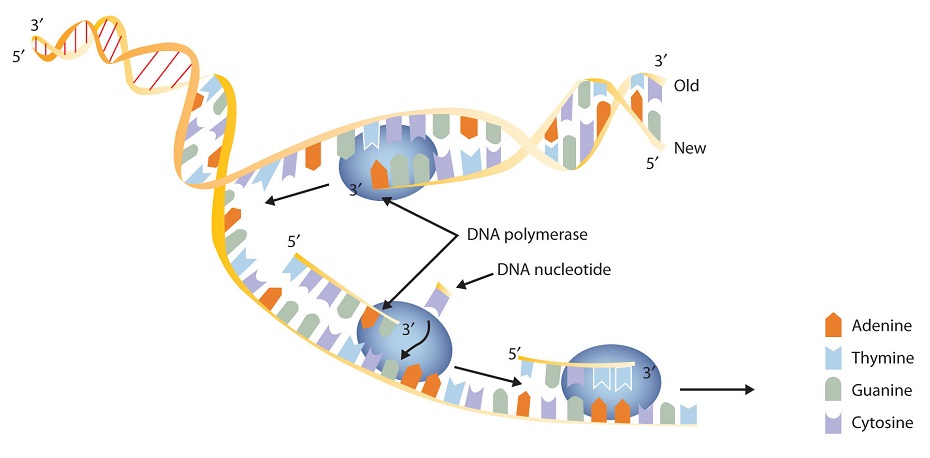
Figure 28.3.1 A Schematic Diagram of DNA Replication. DNA replication occurs by the sequential unzipping of segments of the double helix. Each new nucleotide is brought into position by DNA polymerase and is added to the growing strand by the formation of a phosphate ester bond. Thus, two double helixes form from one, and each consists of one old strand and one new strand, an outcome called semiconservative replications. (This representation is simplified; many more proteins are involved in replication.)
A segment of one strand from a DNA molecule has the sequence 5′‑TCCATGAGTTGA‑3′. What is the sequence of nucleotides in the opposite, or complementary, DNA chain?
Solution
Knowing that the two strands are antiparallel and that T base pairs with A, while C base pairs with G, the sequence of the complementary strand will be 3′‑AGGTACTCAACT‑5′ (can also be written as TCAACTCATGGA).
What do we mean when we say information is encoded in the DNA molecule? An organism’s DNA can be compared to a book containing directions for assembling a model airplane or for knitting a sweater. Letters of the alphabet are arranged into words, and these words direct the individual to perform certain operations with specific materials. If all the directions are followed correctly, a model airplane or sweater is produced.
In DNA, the particular sequences of nucleotides along the chains encode the directions for building an organism. Just as saw means one thing in English and was means another, the sequence of bases CGT means one thing, and TGC means something different. Although there are only four letters—the four nucleotides—in the genetic code of DNA, their sequencing along the DNA strands can vary so widely that information storage is essentially unlimited.
Exercise
A segment of one strand from a DNA molecule has the sequence 5′‑CCAGTGAATTGCCTAT‑3′. What is the sequence of nucleotides in the opposite, or complementary, DNA chain?
- Answer
-
3′‑GGTCACTTAACGGATA‑5′
Contributors and Attributions
Dr. Dietmar Kennepohl FCIC (Professor of Chemistry, Athabasca University)
Prof. Steven Farmer (Sonoma State University)