
Problem 3
- Page ID
- 276159

The identical statistical results for Data Sets 1, 2 and 3 certainly suggests that all three data sets may be equally well explained by the same linear model. Let's look at this more closely. Open the Excel file containing the three data sets. Each data set is on a separate Excel worksheet.
Task 1. For each data set, create a separate scatterplot with a linear trendline. How well does this linear model explain the relationship between X and Y for each data set? What does this imply about the usefulness of using R2 or R as the sole measure of a model's appropriateness?
Task 2. For all three data sets, the value of R2 is relatively small. The linear model of data from the module's introduction
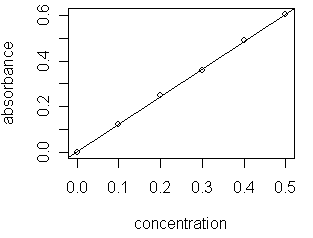
on the other hand, has an R2 of 0.9997. Look carefully at Data Set 2. Is there a mathematical model that might better explain the relationship between X and Y? Remove the linear trendline and try a more appropriate model. You should be able to find a model with an R2 value of nearly 1.
Look carefully at Data Set 3. It appears that the data are linear, so what is the reason for the relatively small value for R2? Edit the data to remove the problem and examine how this changes your model (if necessary, replot the data). You should be able to find a linear model with an R2 value of nearly 1.
After completing these tasks, proceed to the module's summary.